Pamatujete si , jak jsme kdysi dávno zavedli funkci v pluginu Big Data Tools s názvem ZTools , která umožňuje zobrazit aktuální stav proměnných v notebooku Zeppelin? Pamatujete si, že jsme téměř před rokem provedli významné změny v implementaci ZTools?
Naší tradicí je každoročně vydávat velká oznámení o této části Big Data Tools a dnes oznamujeme několik zajímavých změn. Pokud byste si je raději vyzkoušeli sami, zde je odkaz na plugin:
Nové jméno
A co je nejdůležitější, tato funkce se nyní nazývá „State Viewer“. Rozhodli jsme se změnit název, protože State Viewer může implementovat variabilní zobrazení také pro jiné notebooky, nejen pro Zeppelin. Uvažovalo se o několika dalších jménech a výběr nebyl snadný.
Tady to vypadá:
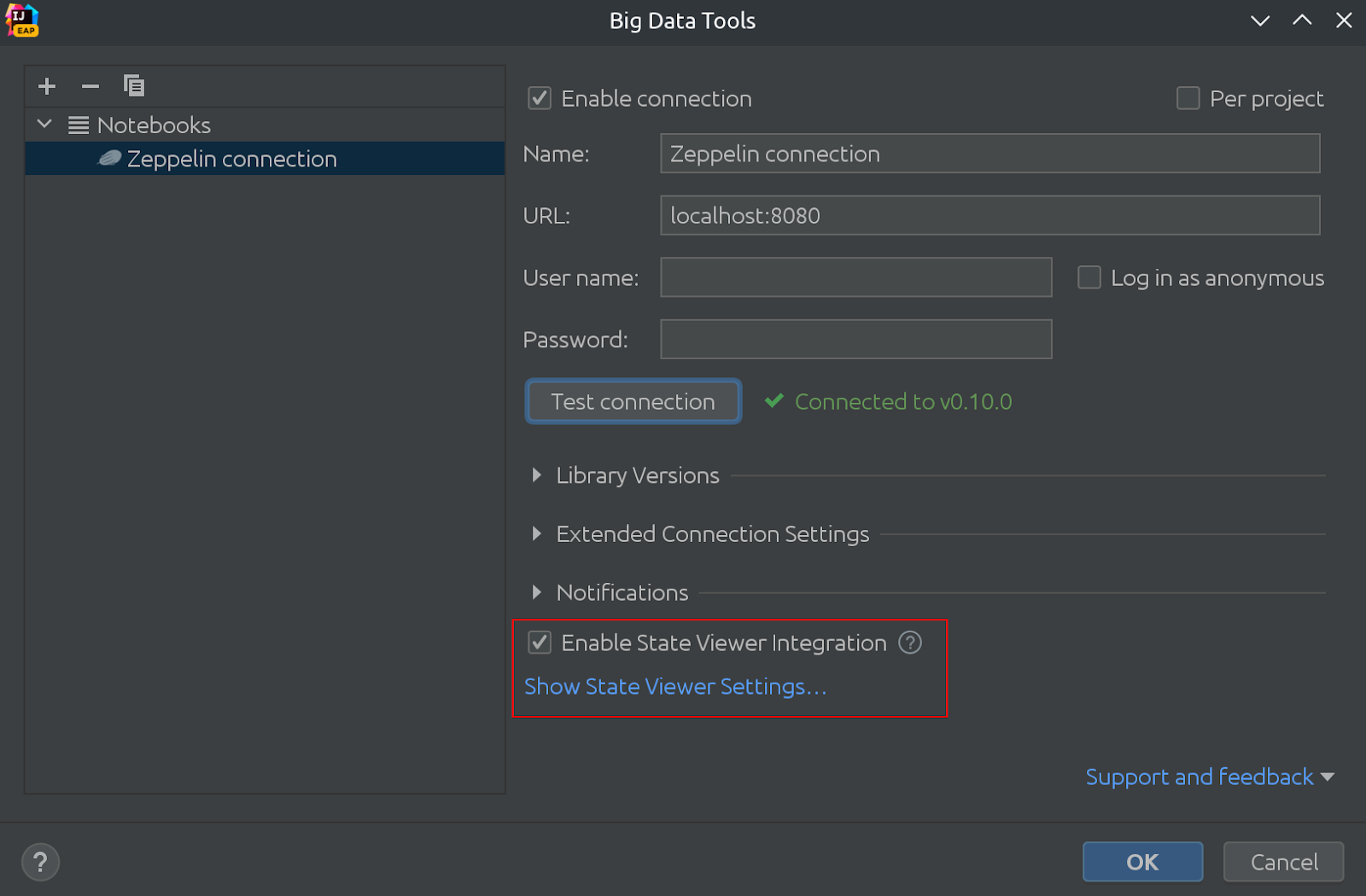
Na stejném obrázku můžete vidět, že Prohlížeč stavu je nyní ve výchozím nastavení povolen!
Tlustý server na tlustého klienta
První významnou změnou, kterou jsme provedli, byl přechod z modelu „tenkého klienta“ na model „tenkého serveru“. To znamená, že IDE nemusí nic instalovat do interpretu Zeppelinu. To je zase výhodné, když instanci Zeppelin plně neovládáte.
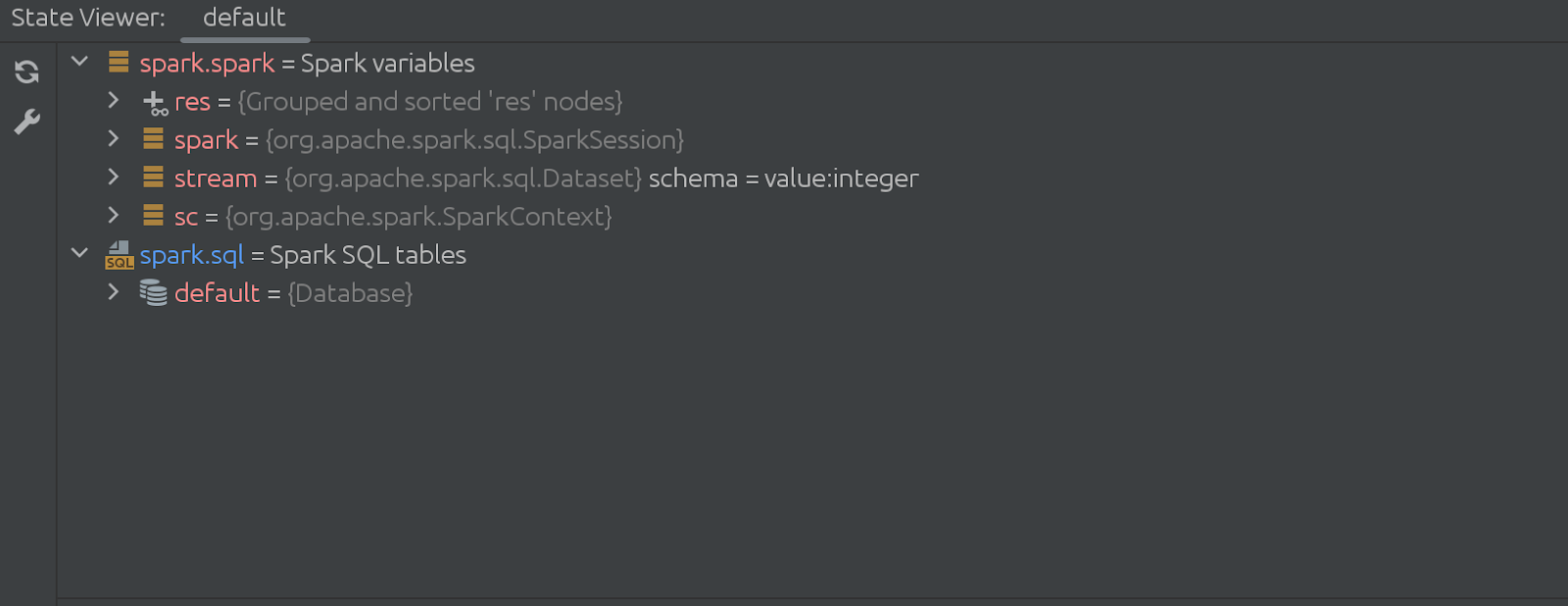
Jak to funguje? Tyto změny jsou spíše evoluční než evoluční. Dříve State Viewer používal spouštění buněk na pozadí pouze k volání metody z knihovny, kterou jsme nainstalovali do interpretu Zeppelin. Nyní se plugin chová jinak, provádí logiku shromažďování dat ze Zeppelinu a odesílá je do okna State Viewer.
Kód skryté (mizí) buňky je také docela působivý. Začíná to takto:
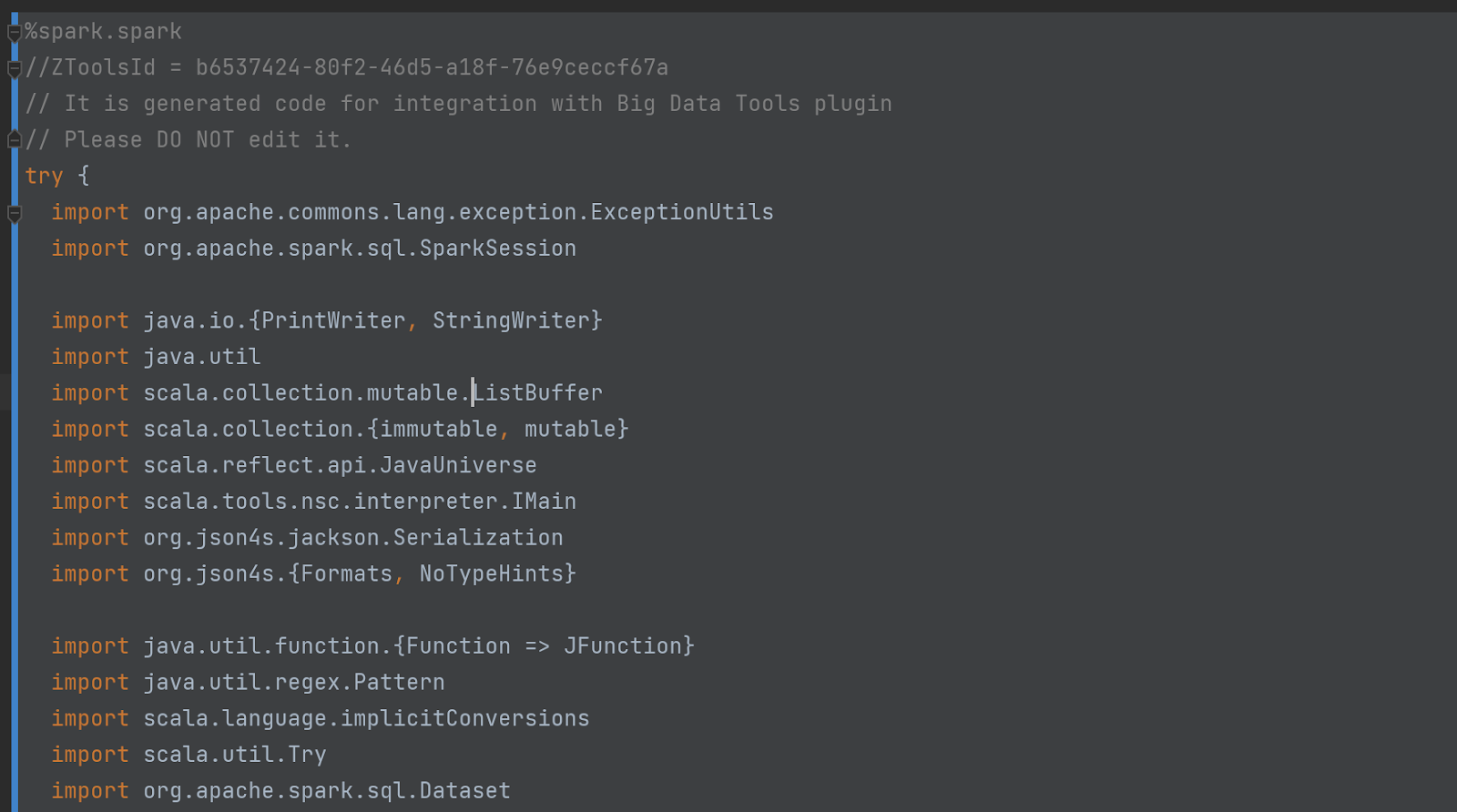
Neberte nás za slovo – podívejte se na kód sami! Chcete-li tak učinit, povolte v nastavení „Režim ladění“:
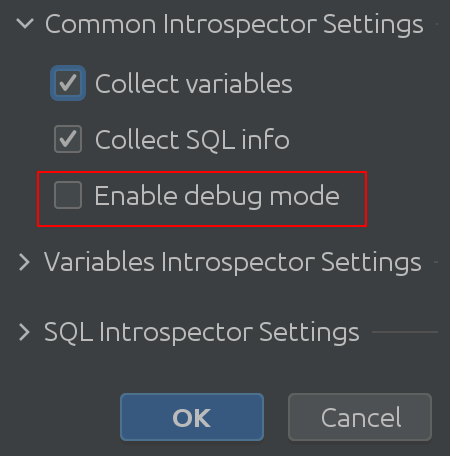
To nás vede k následující významné změně: nastavení prohlížeče State bylo přepracováno.
Nastavení prohlížeče stavu
Plně rozšířené zobrazení nastavení Prohlížeče stavu vypadá takto:
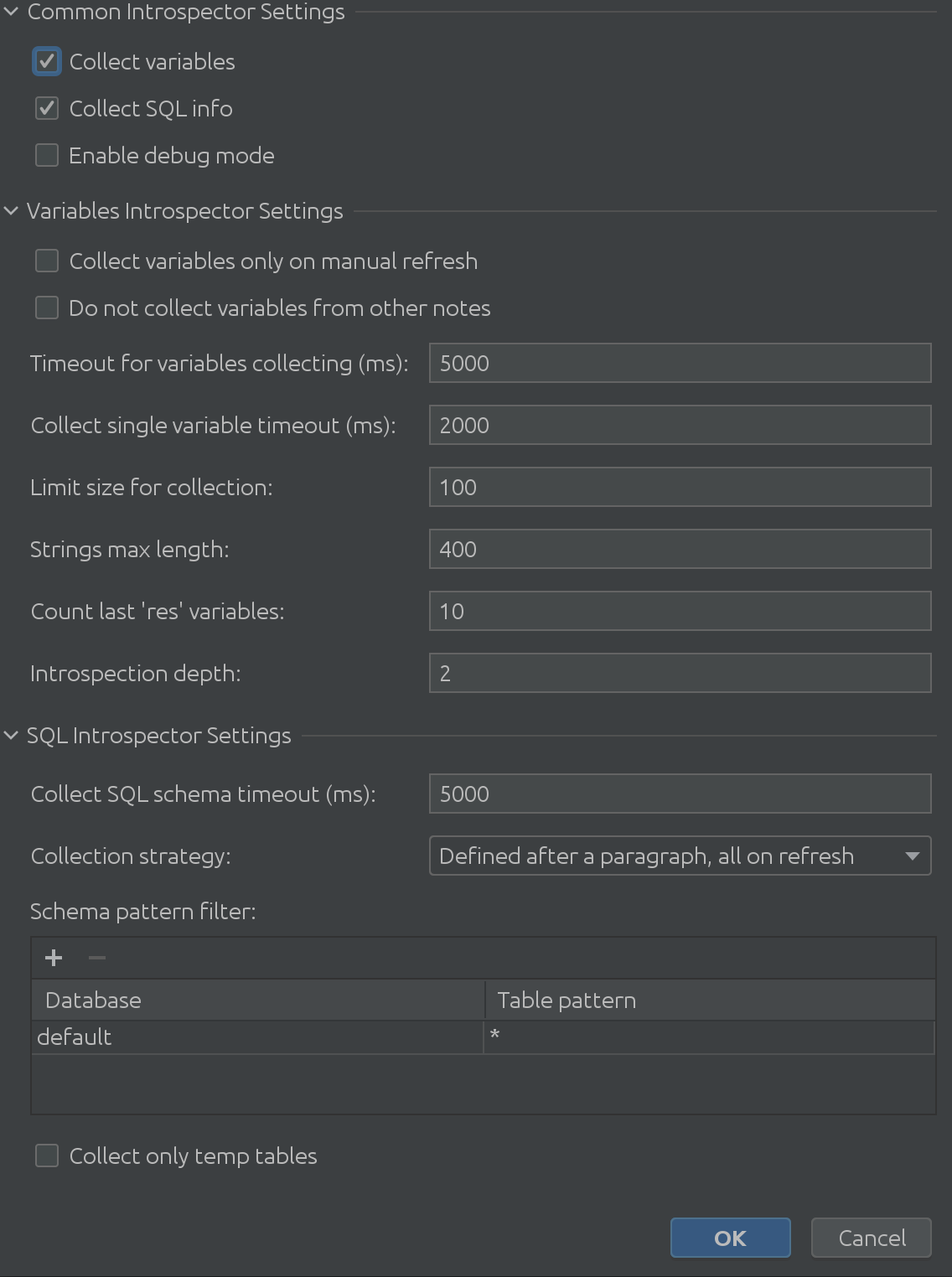
Je to naprosto masivní, že?
Jak můžeme vidět na předchozím snímku obrazovky, skládá se ze 3 hlavních částí:
1. Společná nastavení tlumočníka
2. Variabilní nastavení Introspectoru
3. Nastavení SQL Introspector
Doufejme, že název „Common Interpreter Settings“ je samozřejmý. Můžete povolit nebo zakázat shromažďování informací o proměnných ze Spark SQL a umožňuje vám povolit režim ladění. Je pravda, že je to pro nás, vývojáře pluginů, nejužitečnější, ale můžete to použít k hlubšímu pochopení vnitřního fungování pluginu. Variable Introspector Settings
Cenná zpětná vazba od našich zákazníků nám umožnila pochopit vzrušující rohové případy při introspekci proměnných. Variable Introspector Settings řeší všechny potenciální problémy, se kterými se můžete setkat. Potřebujete introspektovat delší texty? Zvyšte limit velikosti řetězce. Nyní trvá extrahování všech více času? Prodlužte časový limit při čekání, než Zeppelin odpoví. Musíte pracovat s hluboce vnořenými strukturami? Můžete doladit maximální hloubku výkopu.
Nastavení SQL Introspector
Ani jsme si neuvědomili, jak užitečný SQL Introspector bude pro některé naše zákazníky! Potřebovali jsme zjistit, jak složité mohou být scénáře použití napříč mnoha schématy a tabulkami, což nás vedlo k dalšímu vzrušujícímu řešení:
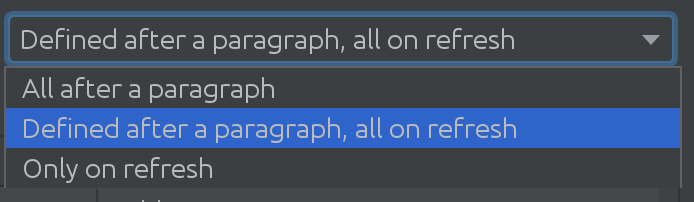
V závislosti na velikosti vaší databáze Spark můžete použít různé strategie, když potřebujete stáhnout změny z databáze Spark. Někdy jsou databáze tak rozsáhlé, že se rozhodneme změny automaticky nevytahovat vůbec.
Všechny tyto změny nás vedly k tomu, že jsme v této verzi standardně zapnuli Big Data Tools.
Také jsme se dozvěděli, že když naši zákazníci pracují se Sparkem, pracují s více než jen s výchozím katalogem. Někdy je „výchozí“ katalog naprosto masivní a potřebují z něj data nějak filtrovat. Proto jsme v SQL Introspector zavedli následující filtr:
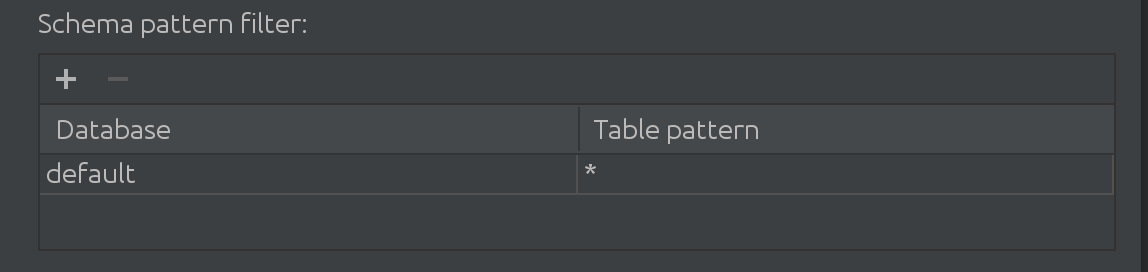
Zde můžete filtrovat a přidávat další katalogy a hledat data pro automatické doplňování a také omezit podmnožinu dotazovaných tabulek v katalogu.
Pokud používáte AWS Glue nebo Hive Metastore, může být užitečné také toto zaškrtávací políčko:

Lepidlo vaší společnosti bude pravděpodobně neuvěřitelně velké a potřebujete pouze data, která tam vložíte během relace.
Prohlížeč stavu je nyní ve výchozím nastavení povolen
Od našeho posledního blogového příspěvku o této funkci jsme zavedli mnoho vylepšení. Jsme velmi vděční našim zákazníkům za jejich trvalou podporu a neustálou zpětnou vazbu – díky nim bylo možné realizovat mnoho změn! Nyní jsme přesvědčeni, že Big Data Tools jsou dostatečně stabilní a flexibilní pro naše široké publikum, aby je mohlo nepřetržitě používat z těchto důvodů:
1. Již nevyžaduje změny v Zeppelinu.
2. Umožňuje vám doladit variabilní introspekci podle vašeho případu použití.
3. Umožňuje vám vyladit introspekci SQL podle kontextu a složitosti vašich úkolů.
4. Mechanika skrytých buněk byla vylepšena.
5. Máme pro naše uživatele metodu, jak zkontrolovat a hluboce porozumět funkčnosti pluginu. udělali další krok, abychom našim zákazníkům umožnili „nás zkontrolovat“ a ujistit se, že děláme jen to, co říkáme, že děláme, a nic víc.
Pokud máte zájem Big Data Tools vyzkoušet, plugin snadno najdete zde .
 E-mail
E-mail