¿Recuerdas hace mucho tiempo cuando introdujimos una función en el complemento de Big Data Tools llamada ZTools que te permite ver el estado actual de las variables en una computadora portátil Zeppelin? ¿Recuerda que hicimos cambios significativos en la implementación de ZTools hace casi un año?
Es nuestra tradición hacer grandes anuncios sobre esta parte de Big Data Tools todos los años, y hoy estamos anunciando varios cambios emocionantes. Si prefiere comprobarlos usted mismo, aquí está el enlace al complemento:
Nuevo nombre
Lo más importante es que esta función ahora se llama "Visor de estado". Decidimos cambiar el nombre porque State Viewer también puede implementar visualización variable para otros portátiles, no solo para Zeppelin. Se estaban considerando algunos otros nombres, y la elección no fue fácil.
Así es como se ve:
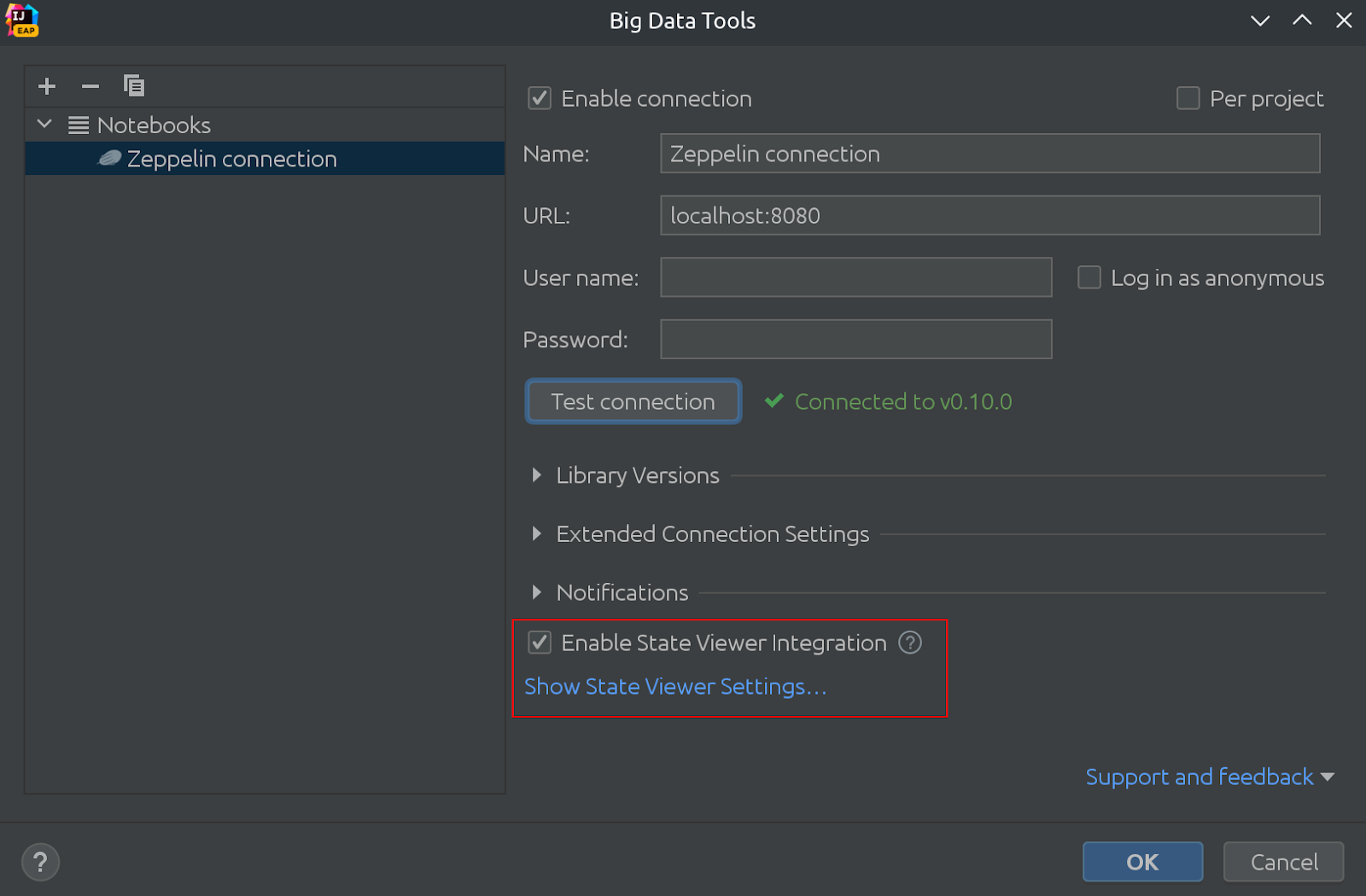
¡En la misma imagen, puede ver que el Visor de estado ahora está habilitado de manera predeterminada!
Servidor grueso a cliente grueso
El primer cambio significativo que hicimos fue pasar de un modelo de "cliente ligero" a un modelo de "servidor ligero". Esto significa que el IDE no necesita instalar nada en el intérprete de Zeppelin. A su vez, esto es beneficioso cuando no controla completamente la instancia de Zeppelin.
¿Como funciona? Bueno, estos cambios son evolutivos más que evolutivos. Anteriormente, State Viewer usaba la ejecución de celdas en segundo plano solo para llamar a un método de una biblioteca que instalamos en el intérprete de Zeppelin. Ahora el complemento actúa de manera diferente, ejecutando la lógica de recopilación de datos de Zeppelin y enviándolos a la ventana del Visor de estado.
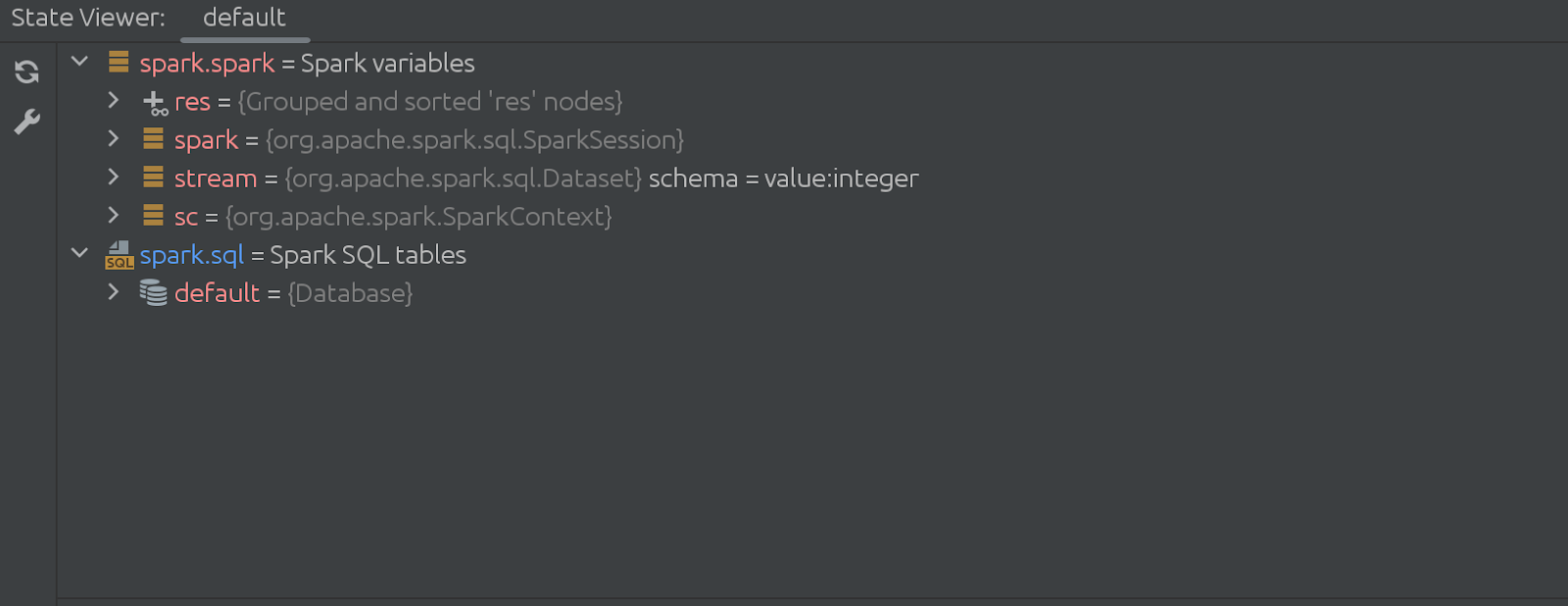
El código de la celda oculta (que desaparece) también es bastante impresionante. Comienza así:
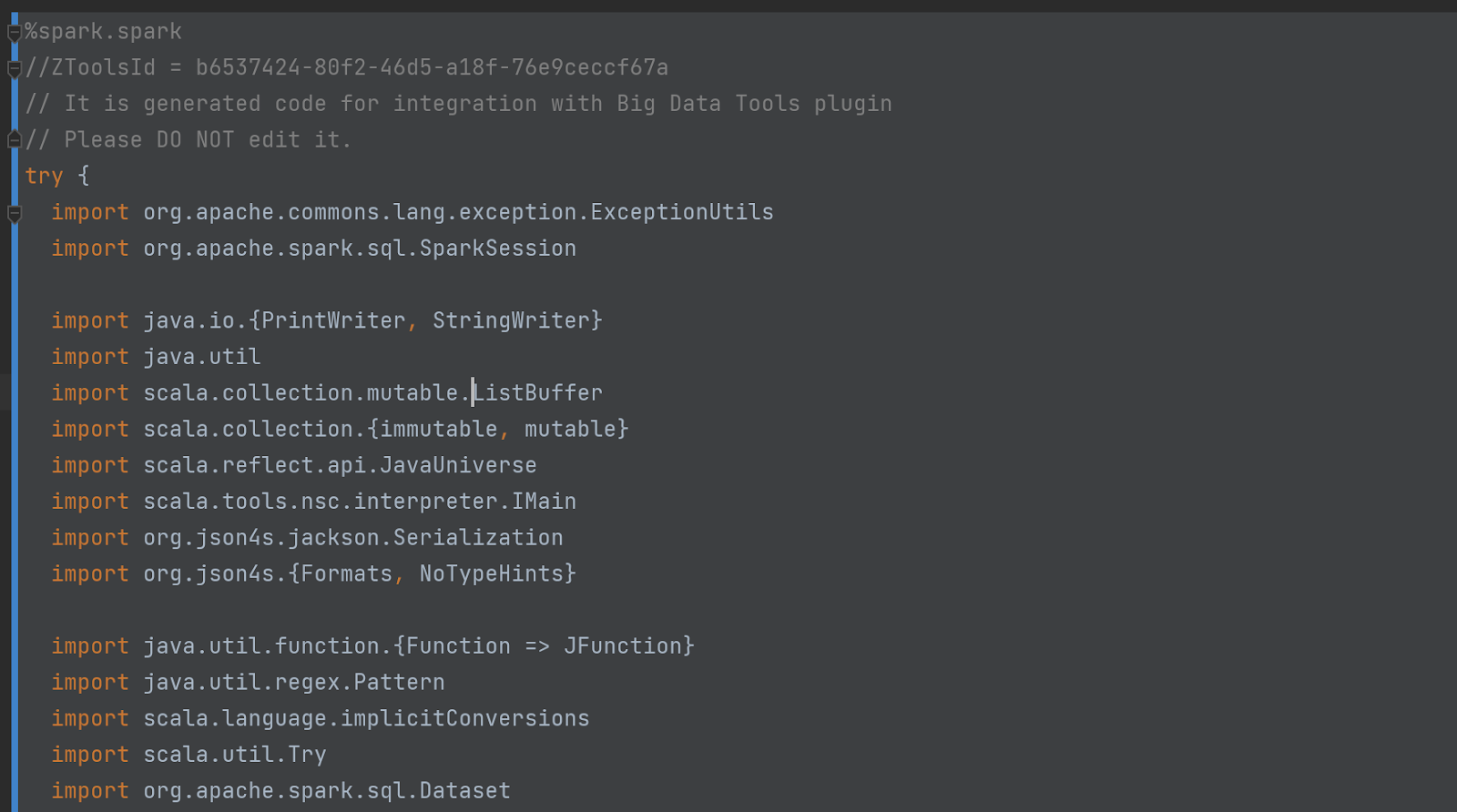
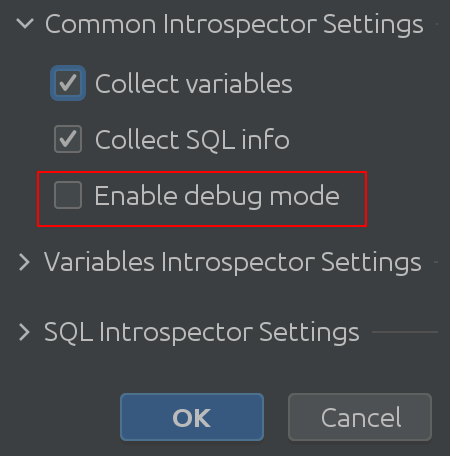
No confíe en nuestra palabra: ¡compruebe el código usted mismo! Para hacerlo, habilite el "Modo de depuración" en la configuración:
Esto nos lleva al siguiente cambio significativo: la configuración del visor de estado se ha renovado.
Configuración del visor de estado
La vista completamente ampliada de la configuración de State Viewer se ve así:
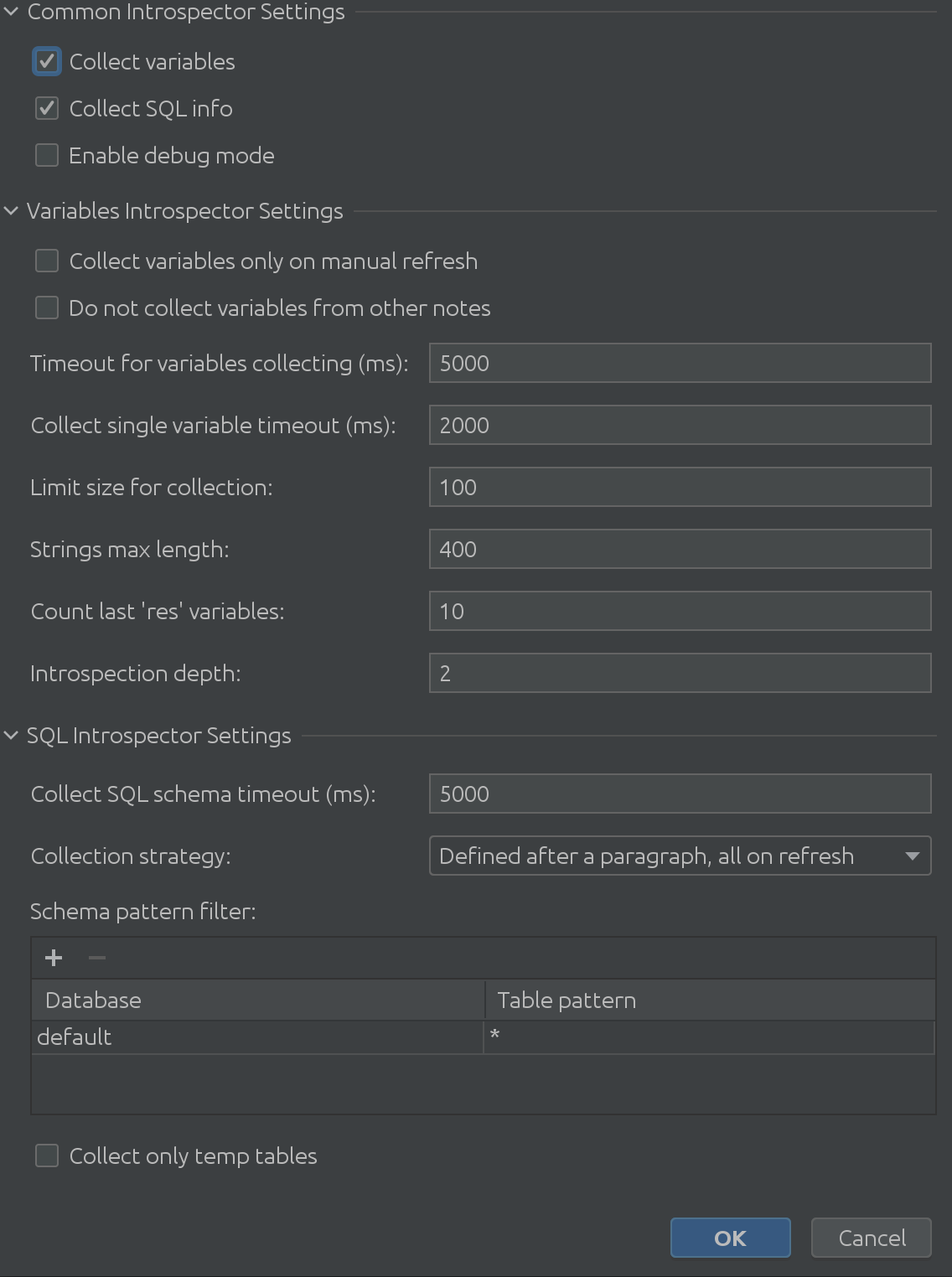
Es absolutamente enorme, ¿verdad?
Como podemos ver en la captura de pantalla anterior, consta de 3 partes principales:
1. Configuración común del intérprete
2. Configuración de Introspector de variables
3. Configuración del Introspector de SQL
Con suerte, el nombre "Configuración común del intérprete" se explica por sí mismo. Puede habilitar o deshabilitar la recopilación de información sobre las variables de Spark SQL y le permite habilitar el modo de depuración. Es cierto que esto es más útil para nosotros, los desarrolladores de complementos, pero puede usarlo para obtener una comprensión más profunda del funcionamiento interno del complemento. Configuración de introspector variable
Los valiosos comentarios de nuestros clientes nos han dado una comprensión de los casos extremos emocionantes cuando se introspeccionan las variables. La configuración del introspector variable aborda todos los posibles problemas que podría encontrar. ¿Necesitas introspeccionar textos más largos? Aumente el límite del tamaño de la cadena. ¿Ahora se necesita más tiempo para extraerlos todos? Aumente el tiempo de espera mientras espera que Zeppelin responda. ¿Tiene que trabajar con estructuras profundamente anidadas? Puede ajustar la profundidad máxima de excavación.
Configuración de SQL Introspector
¡Ni siquiera nos dimos cuenta de lo útil que sería SQL Introspector para algunos de nuestros clientes! Necesitábamos descubrir qué tan complejos pueden ser los escenarios de uso en muchos esquemas y tablas, lo que nos llevó a la siguiente solución emocionante:
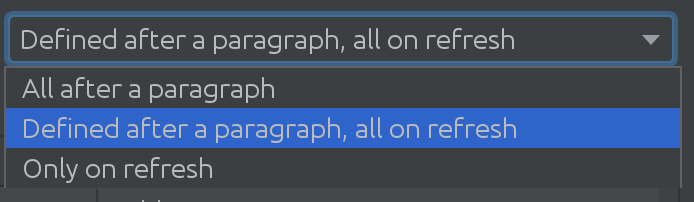
Según el tamaño de su base de datos de Spark, puede usar diferentes estrategias cuando necesite extraer cambios de la base de datos de Spark. A veces, las bases de datos son tan extensas que decidimos no extraer cambios automáticamente.
Todos estos cambios nos llevaron a activar Big Data Tools de forma predeterminada en esta versión.
También aprendimos que cuando nuestros clientes trabajan con Spark, trabajan con más que solo el catálogo predeterminado. A veces, el catálogo "predeterminado" es absolutamente masivo y necesitan filtrar datos de alguna manera. Es por eso que introdujimos el siguiente filtro en SQL Introspector:
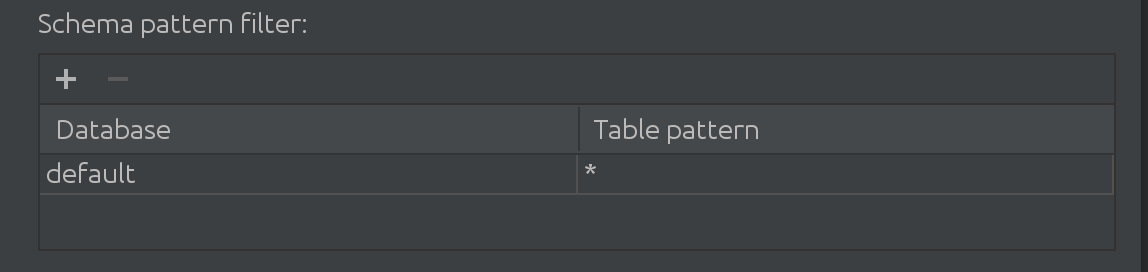
Aquí puede filtrar y agregar más catálogos para buscar datos para el autocompletado, así como limitar el subconjunto de tablas consultadas dentro de un catálogo.
Si usa AWS Glue o Hive Metastore, también puede encontrar útil esta casilla de verificación:

Es probable que el Glue de su empresa sea increíblemente grande, y solo necesita los datos que ingresa allí durante su sesión.
State Viewer ahora está habilitado de forma predeterminada
Hemos introducido muchas mejoras desde nuestra última publicación de blog sobre esta característica. Estamos muy agradecidos con nuestros clientes por su apoyo continuo y sus comentarios continuos: ¡fue posible implementar muchos cambios gracias a ellos! Ahora estamos seguros de que Big Data Tools es lo suficientemente estable y flexible para que nuestra audiencia general pueda usarla continuamente por estas razones:
1. Ya no requiere cambios en Zeppelin.
2. Le permite ajustar la introspección de variables a su caso de uso.
3. Le permite afinar la introspección de SQL según el contexto y la complejidad de sus tareas.
4. Se ha mejorado la mecánica de las celdas ocultas.
5. Tenemos un método para que nuestros usuarios verifiquen y comprendan profundamente la funcionalidad del complemento. dio un paso adicional para permitir que nuestros clientes "vigilen cómo estamos" y se aseguren de que estamos haciendo solo lo que decimos que estamos haciendo, y nada más.
Si está interesado en probar Big Data Tools, puede encontrar fácilmente el complemento aquí .
 Correo electrónico
Correo electrónico