Vous souvenez-vous d’un long Il y a longtemps, quand nous avons introduit Une fonctionnalité du plugin Big Data Tools appelée Outils de travail Qui vous permet de visualiser l’état actuel des variables dans un bloc-notes Zeppelin? Vous souvenez-vous que nous avons apporté des changements importants à l’implémentation de ZTools il y a presque un an?
C’est notre tradition de faire de grandes annonces sur cette partie de Outils de Big Data Chaque année, et aujourd’hui, nous annonçons de multiples changements passionnants. Si vous préférez simplement les vérifier vous-même, voici le lien vers le plugin:
Nouveau nom
Plus important encore, cette fonctionnalité est maintenant appelée "State Viewer". Nous avons décidé de changer le nom parce que State Viewer peut implémenter l’affichage variable pour d’autres ordinateurs portables aussi, pas seulement pour Zeppelin. Il y avait quelques autres noms envisagés, et le choix n’a pas été facile.
Voici à quoi ça ressemble:
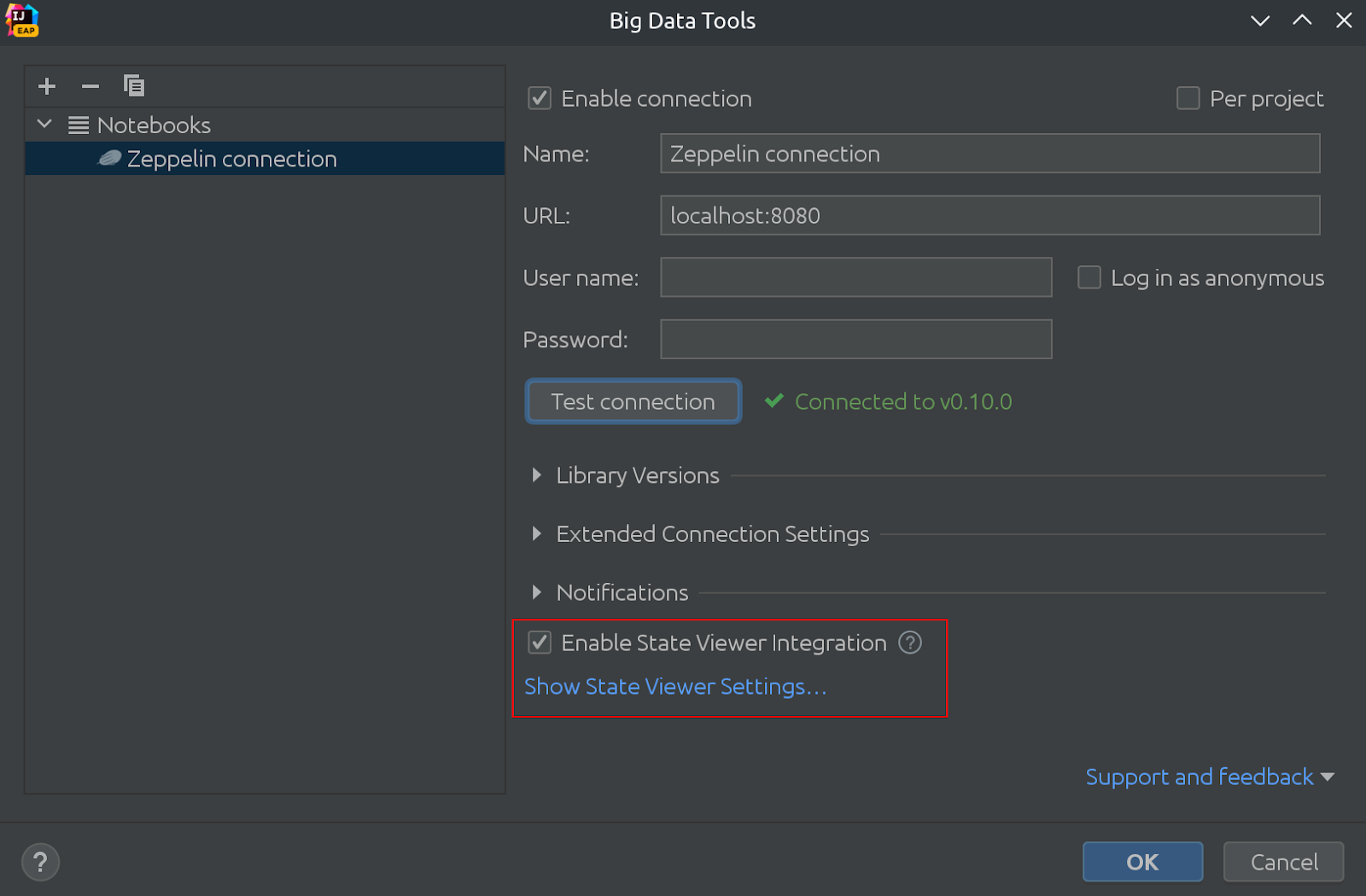
Dans la même image, vous pouvez voir que le visualiseur d’état est maintenant activé par défaut!
Serveur épais vers client épais
Le premier changement significatif que nous avons fait a été le passage d’un modèle «client mince» à un modèle «serveur mince». Cela signifie que l’ide n’a pas besoin d’installer quoi que ce soit dans l’interpréteur de Zeppelin. À son tour, cela est bénéfique lorsque vous ne contrôlez pas entièrement le Zeppelin instance.
Comment ça marche? Eh bien, ces changements sont plutôt évolutifs qu’évolutifs. Auparavant, State Viewer utilisait l’exécution de cellule de fond uniquement pour appeler une méthode depuis une bibliothèque que nous avons installée dans l’interpréteur Zeppelin. Maintenant, le plugin agit différemment, exécutant la logique de collecte de données de Zeppelin et l’envoyant dans la fenêtre du visuateur d’état.
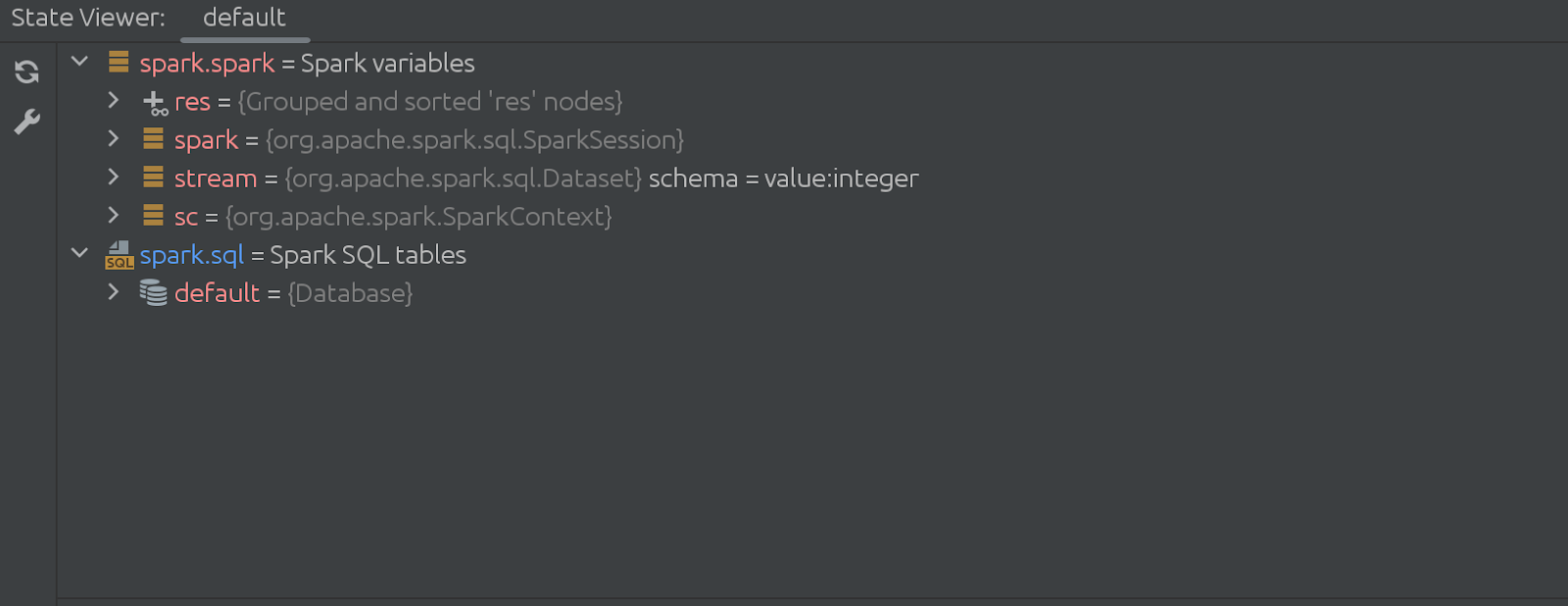
Le code de la cellule cachée (qui disparaît) est aussi assez impressionnant. Cela commence comme ceci:
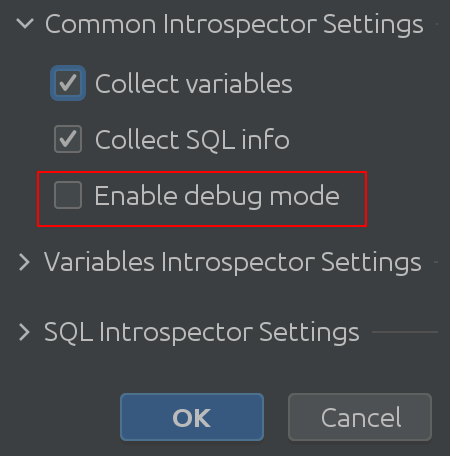
Ne nous croyez pas sur parole - consultez le code vous-même! Pour ce faire, activez "Debug mode" dans les paramètres:
Cela nous amène au changement significatif suivant: les paramètres du visualiseur d’état ont été revamped.
Paramètres du visualiseur d’état
La vue complète des paramètres de State Viewer ressemble à ceci:
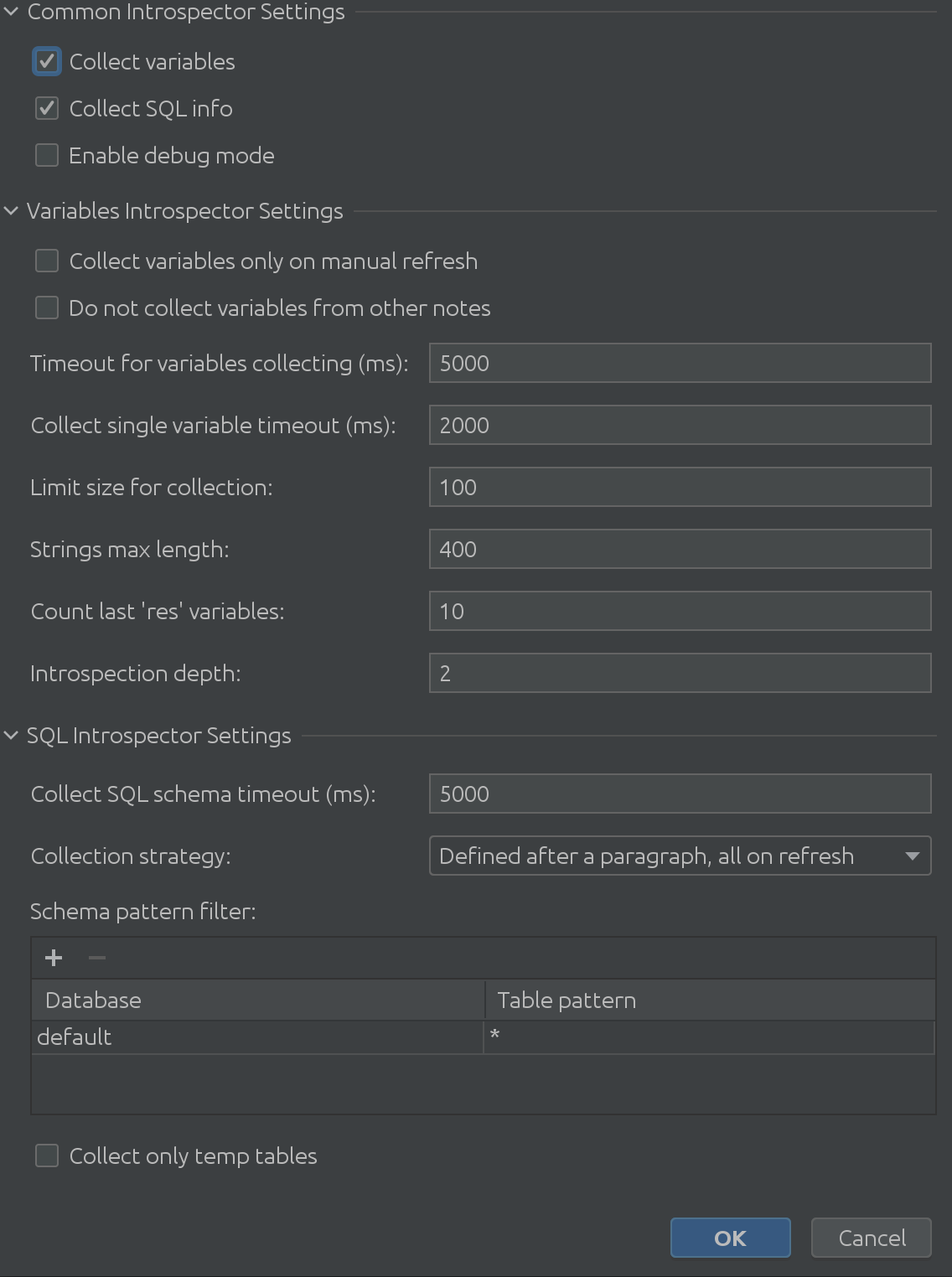
C’est absolument massif, non?
Comme nous pouvons le voir dans la capture d’écran précédente, il se compose de 3 parties principales:
1. Paramètres courants de l’interprète
2. Paramètres variables de l’introspecteur
3. Paramètres SQL Introspector
Espérons que le nom "Common Interpreter Settings" soit explicite. Vous pouvez activer ou désactiver la collecte d’informations sur les variables de Spark SQL, et il vous permet d’activer le mode debug. Certes, c’est très utile pour nous, les développeurs de plugin, mais vous pouvez l’utiliser pour avoir une compréhension plus profonde du fonctionnement interne du plugin. Paramètres variables de l’introspecteur
Les commentaires précieux de nos clients nous ont permis de comprendre des cas de coin passionnants lors de l’introspection de variables. Les paramètres d’introspecteur Variable répondent à tous les problèmes potentiels que vous pourriez rencontrer. Besoin d’introspecter des textes plus longs? Augmentez la limite de la taille de la chaîne. Maintenant, il faut plus de temps pour les extraire tous? Augmentez le délai d’attente en attendant que Zeppelin réponde. Vous devez travailler avec des structures profondément imbriquées? Vous pouvez affiner la profondeur de creusement maximale.
Paramètres SQL Introspector
Nous n’avons même pas réalisé à quel point SQL Introspector serait utile pour certains de nos clients! Nous avions besoin de découvrir à quel point les scénarios d’utilisation peuvent être complexes à travers de nombreux schémas et tableaux, ce qui nous a conduit à la prochaine solution passionnante:
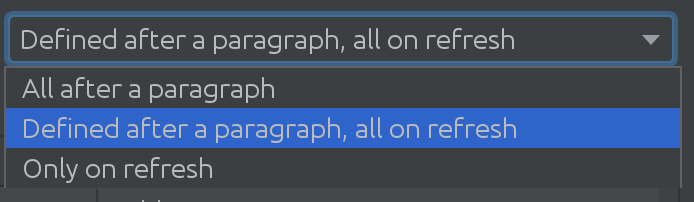
En fonction de la taille de votre base de données Spark, vous pouvez utiliser différentes stratégies lorsque vous devez extraire des modifications de la base de données Spark. Parfois, les bases de données sont si étendues que nous déciderons de ne pas retirer les modifications automatiquement du tout.
Tous ces changements nous ont amenés à activer les outils Big Data par défaut dans cette version.
Nous avons également appris que lorsque nos clients travaillent avec Spark, ils travaillent avec plus que le catalogue par défaut. Parfois, le catalogue "par défaut" est absolument massif, et ils ont besoin de filtrer les données en quelque sorte. C’est pourquoi nous avons introduit le filtre suivant dans l’introspector SQL:
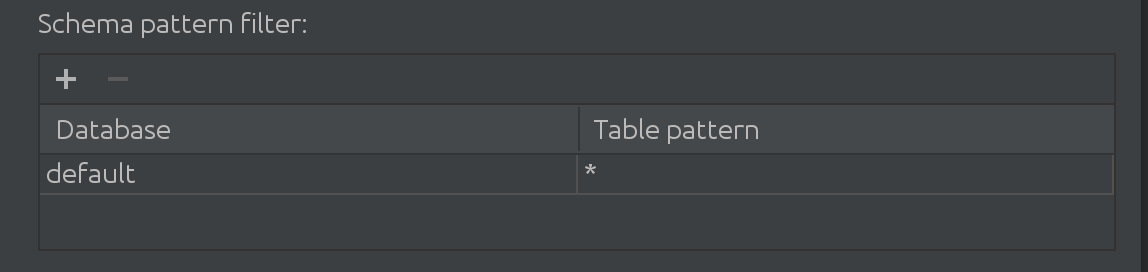
Ici, vous pouvez filtrer et ajouter plus de catalogues pour rechercher des données pour l’autocomplétion, ainsi que limiter le sous-ensemble de tables recherchées à l’intérieur d’un catalogue.
Si vous utilisez AWS Glue ou Hive Metastore, vous pourriez également trouver cette case à cocher utile:

La colle de votre entreprise est susceptible d’être incroyablement grande, et vous n’avez besoin que des données que vous y mettez pendant votre session.
State Viewer est maintenant activé par défaut
Nous avons introduit de nombreuses améliorations depuis notre dernier article de blog sur cette fonctionnalité. Nous sommes très reconnaissants à nos clients pour leur soutien continu et leurs commentaires continus - il a été possible de mettre en œuvre de nombreux changements grâce à eux! Nous sommes maintenant convaincus que les outils de Big Data sont suffisamment stables et flexibles pour que notre public général puisse les utiliser en permanence pour les raisons suivantes:
1. Il ne nécessite plus de changements de Zeppelin.
2. Il vous permet d’affiner l’introspection variable à votre cas d’utilisation.
3. Il vous permet d’ajuster l’introspection SQL en fonction du contexte et de la complexité de vos tâches.
4. La mécanique des cellules cachées a été améliorée.
5. Nous avons une méthode pour nos utilisateurs de vérifier et de comprendre en profondeur les fonctionnalités du plugin. A pris une mesure supplémentaire pour permettre à nos clients de «vérifier sur nous» et de s’assurer que nous faisons seulement ce que nous disons que nous faisons, et pas plus.
Si vous êtes intéressé à essayer des outils de Big Data, vous pouvez facilement trouver le plugin ici.......
 Courriel:
Courriel: