Emlékszel még régre, amikor a Big Data Tools beépülő moduljában bevezettük a ZTools nevű funkciót, amely lehetővé teszi a változók aktuális állapotának megtekintését egy Zeppelin notebookban? Emlékszel, hogy majdnem egy éve jelentős változtatásokat hajtottunk végre a ZTools implementációjában?
Hagyományunk, hogy évente nagy bejelentéseket teszünk a Big Data Tools ezen részével kapcsolatban, ma pedig több izgalmas változást is bejelentünk. Ha inkább csak magad szeretnéd megnézni őket, itt a link a pluginhoz:
Új név
A legfontosabb, hogy ennek a funkciónak a neve „State Viewer”. Azért döntöttünk a név megváltoztatása mellett, mert a State Viewer nem csak a Zeppelinnél, hanem más notebookoknál is képes a változó megtekintésére. Néhány más nevet is fontolgattak, és a választás nem volt könnyű.
Így néz ki:
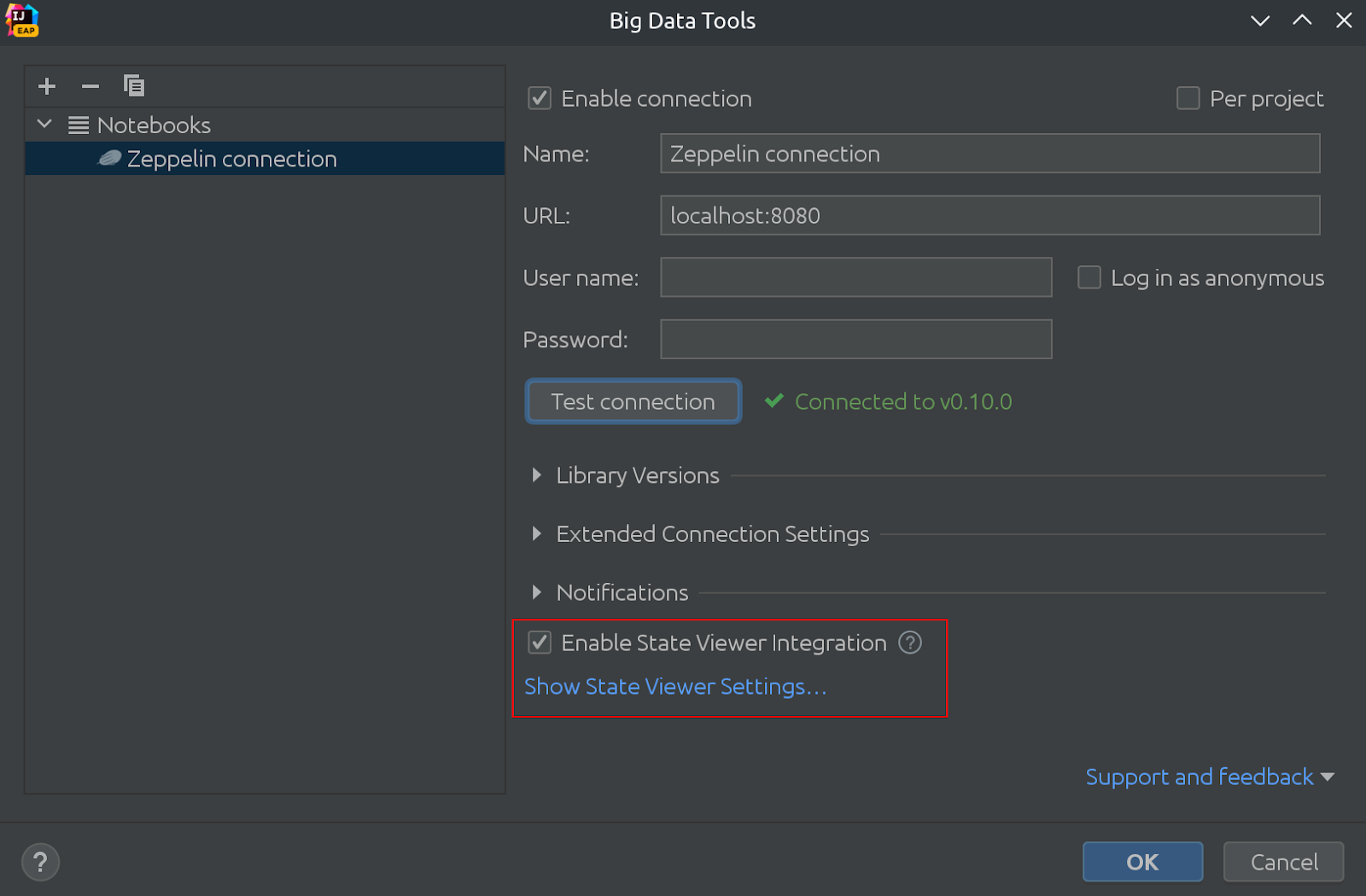
Ugyanezen a képen látható, hogy a State Viewer most már alapból engedélyezve van!
Vastag szerverről vastag kliensre
Az első jelentős változtatás, amit végrehajtottunk, a „vékony kliensről” a „vékony szerver” modellre való átállás volt. Ez azt jelenti, hogy az IDE-nek nem kell semmit telepítenie a Zeppelin értelmezőjébe. Ez viszont akkor előnyös, ha nem irányítja teljesen a Zeppelin példányt.
Hogyan működik? Nos, ezek a változások inkább evolúciósak, mint evolúciósak. Korábban a State Viewer a háttérben végrehajtott cellavégrehajtást csak arra használta, hogy meghívjon egy metódust a Zeppelin interpreterbe telepített könyvtárból. Most a plugin másként működik, végrehajtja a Zeppelin adatgyűjtési logikáját, és elküldi a State Viewer ablakba.
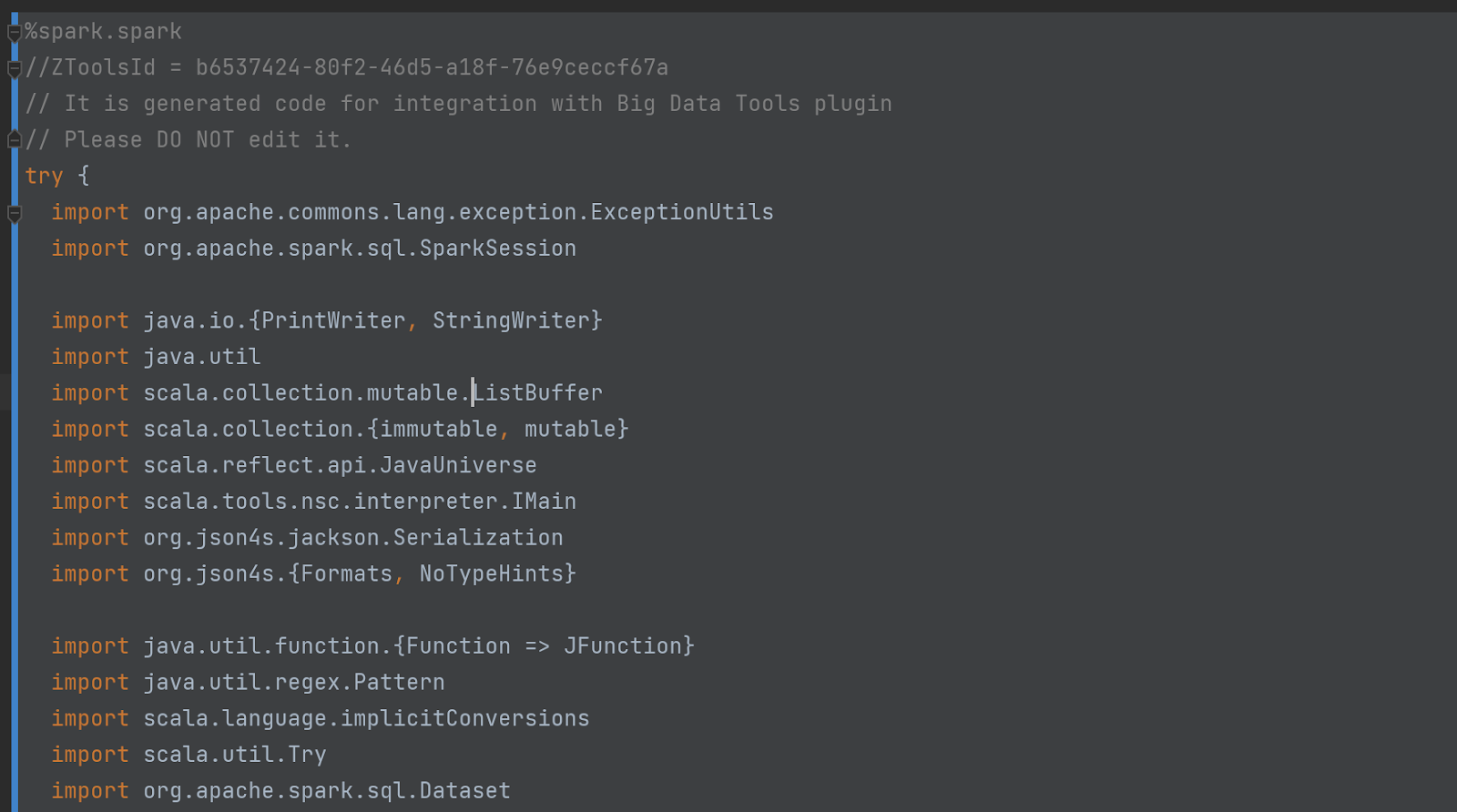
A rejtett (eltűnő) cella kódja is elég lenyűgöző. Így kezdődik:
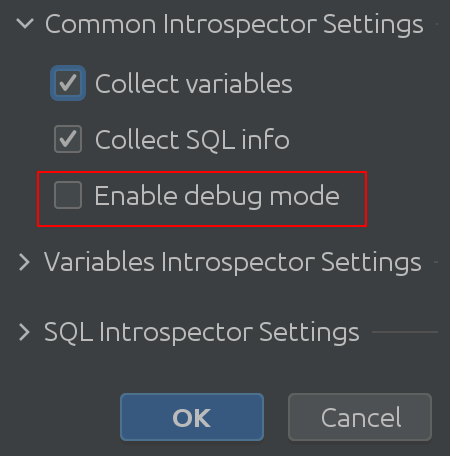
Ne fogadjon szót – nézze meg a kódot saját maga! Ehhez engedélyezze a „Hibakeresés módot” a beállításokban:
Ez a következő jelentős változáshoz vezet: a State viewer beállításai megújultak.
Állítsa be a megjelenítő beállításait
A State Viewer beállításainak teljesen kibontott nézete így néz ki:
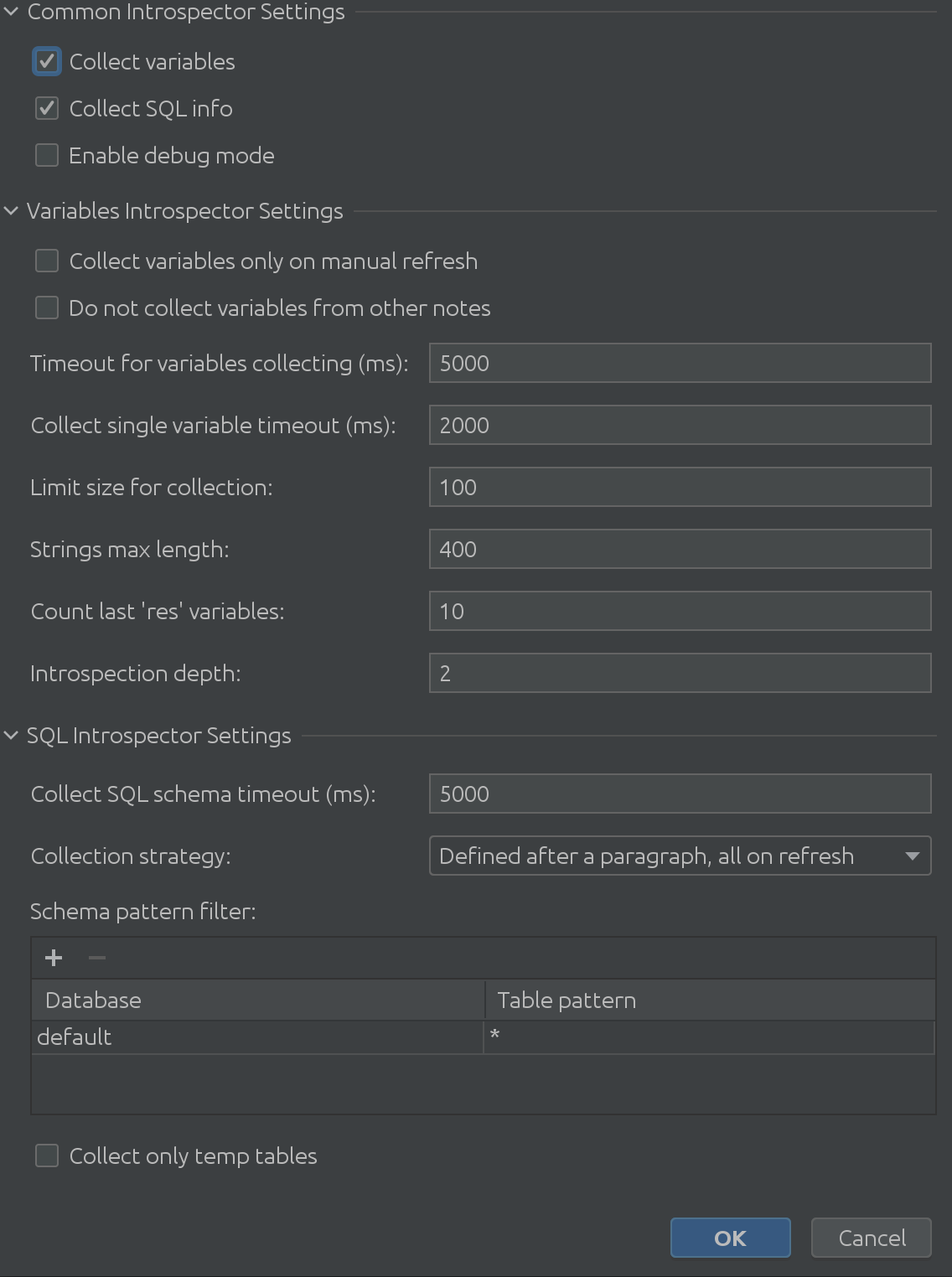
Teljesen masszív, igaz?
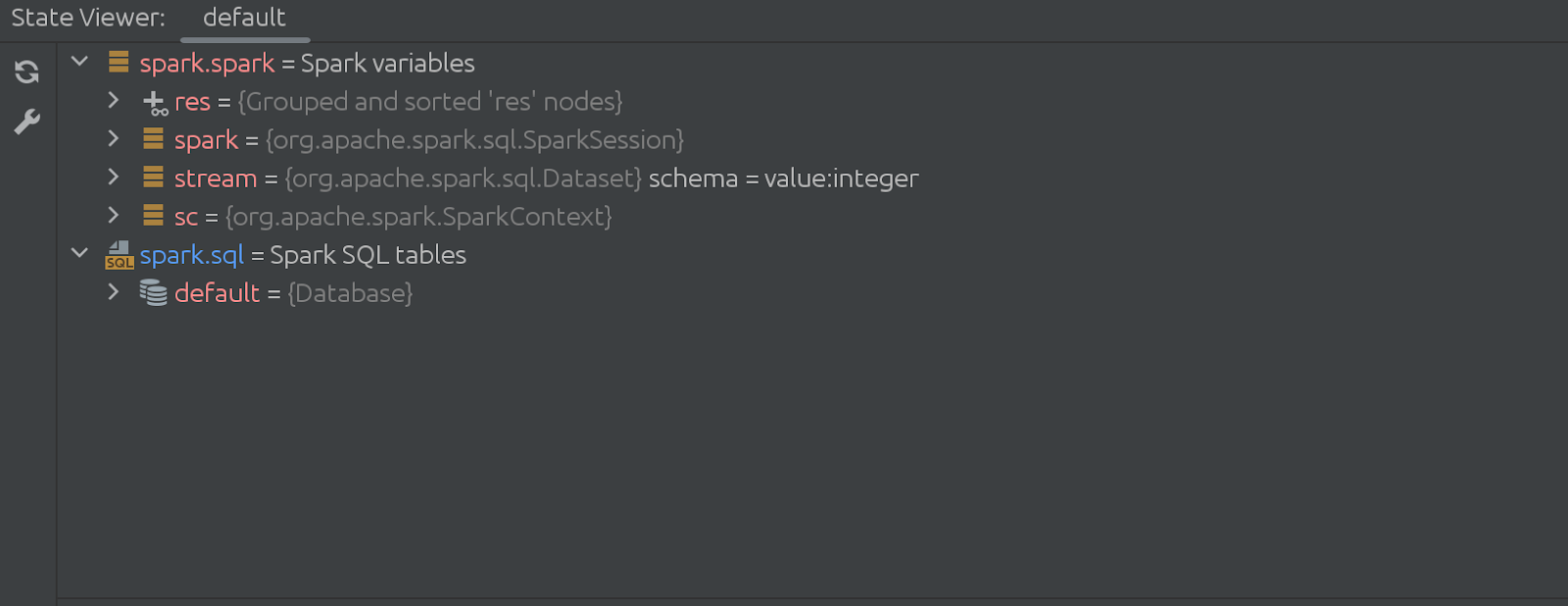
Amint az előző képernyőképen láthattuk, 3 fő részből áll:
1. Közös tolmácsbeállítások
2. Változó Introspector beállítások
3. Az SQL Introspector beállításai
Remélhetőleg a „Közös tolmácsbeállítások” elnevezés magától értetődő. Engedélyezheti vagy letilthatja a Spark SQL változóival kapcsolatos információk gyűjtését, és lehetővé teszi a hibakeresési mód engedélyezését. Kétségtelenül ez a leghasznosabb számunkra, a beépülő modul fejlesztői számára, de felhasználhatja a bővítmény belső működésének mélyebb megértésére. Változó Introspector beállítások
Az ügyfeleinktől kapott értékes visszajelzések alapján megértettük az izgalmas sarkalatos eseteket a változók betekintése során. A Variable Introspector Settings kezeli az összes lehetséges problémát, amellyel találkozhat. Be kell tekintenie a hosszabb szövegeket? Növelje a karakterlánc méretének korlátját. Most több időbe telik mindet kivonni? Növelje az időtúllépést, amíg a Zeppelin válaszára vár. Mélyen beágyazott struktúrákkal kell dolgoznia? Finomhangolhatja a maximális ásási mélységet.
Az SQL Introspector beállításai
Nem is sejtettük, milyen hasznos lehet az SQL Introspector néhány ügyfelünk számára! Ki kellett derítenünk, hogy a használati forgatókönyvek milyen bonyolultak lehetnek sok sémában és táblázatban, ami elvezetett minket a következő izgalmas megoldáshoz:
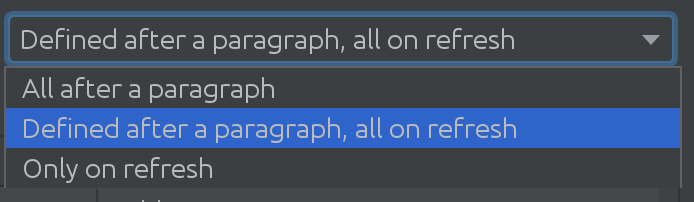
A Spark-adatbázis méretétől függően különböző stratégiákat használhat, amikor módosításokat kell lekérnie a Spark-adatbázisból. Néha az adatbázisok olyan kiterjedtek, hogy úgy döntünk, hogy egyáltalán nem vonjuk be automatikusan a változtatásokat.
Mindezek a változtatások arra késztették, hogy ebben a kiadásban alapértelmezés szerint bekapcsoljuk a Big Data Tools szolgáltatást.
Azt is megtudtuk, hogy amikor ügyfeleink a Sparkkal dolgoznak, nem csupán az alapértelmezett katalógussal dolgoznak. Néha az „alapértelmezett” katalógus teljesen hatalmas, és valahogyan ki kell szűrniük belőle az adatokat. Ezért vezettük be a következő szűrőt az SQL Introspectorban:
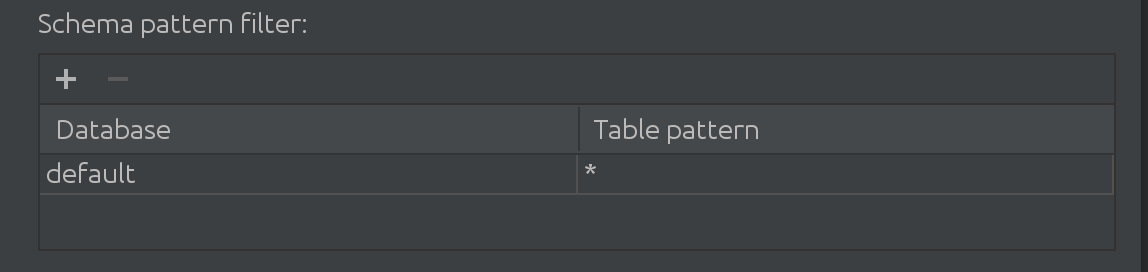
Itt szűrhet és további katalógusokat adhat hozzá az automatikus kiegészítéshez szükséges adatok kereséséhez, valamint korlátozhatja a lekérdezett táblák részhalmazát a katalóguson belül.
Ha AWS ragasztót vagy Hive Metastore-t használ, ez a jelölőnégyzet is hasznosnak találhatja:

Cége ragasztója valószínűleg hihetetlenül nagy, és csak azokra az adatokra van szüksége, amelyeket a munkamenet során elhelyezett.
A State Viewer most alapértelmezés szerint engedélyezve van
A funkcióval kapcsolatos legutóbbi blogbejegyzésünk óta számos fejlesztést vezettünk be. Nagyon köszönjük ügyfeleinknek a folyamatos támogatást és a folyamatos visszajelzést – sok változást sikerült megvalósítani miattuk! Most már biztosak vagyunk abban, hogy a Big Data Tools kellően stabil és rugalmas ahhoz, hogy általános közönségünk folyamatosan használni tudja az alábbi okok miatt:
1. A továbbiakban nem igényel változtatásokat a Zeppelinben.
2. Lehetővé teszi a változó önellenőrzés finomhangolását a használati esetre.
3. Lehetővé teszi az SQL önvizsgálatának hangolását a feladatok kontextusának és összetettségének megfelelően.
4. Javult a rejtett sejtek mechanikája.
5. Van egy módszerünk a felhasználóink számára a bővítmény működésének ellenőrzésére és mélyreható megértésére. egy további lépést tett annak érdekében, hogy ügyfeleink „ellenőrizhessenek minket”, és megbizonyosodjanak arról, hogy csak azt tesszük, amit mondunk, és ne többet.
Ha érdekli a Big Data Tools kipróbálása, itt könnyen megtalálhatja a bővítményt.
 E-mail
E-mail