Ricordi molto tempo fa quando abbiamo introdotto una funzionalità nel plug-in Big Data Tools chiamata ZTools che ti consente di visualizzare lo stato corrente delle variabili in un taccuino Zeppelin? Ricordi che abbiamo apportato modifiche significative all'implementazione di ZTools quasi un anno fa?
È nostra tradizione fare ogni anno grandi annunci su questa parte di Big Data Tools e oggi annunciamo numerosi cambiamenti entusiasmanti. Se preferisci controllarli tu stesso, ecco il link al plugin:
Nuovo nome
Ancora più importante, questa funzione è ora chiamata "State Viewer". Abbiamo deciso di cambiare il nome perché State Viewer può implementare la visualizzazione variabile anche per altri notebook, non solo per Zeppelin. C'erano alcuni altri nomi presi in considerazione e la scelta non è stata facile.
Ecco come appare:
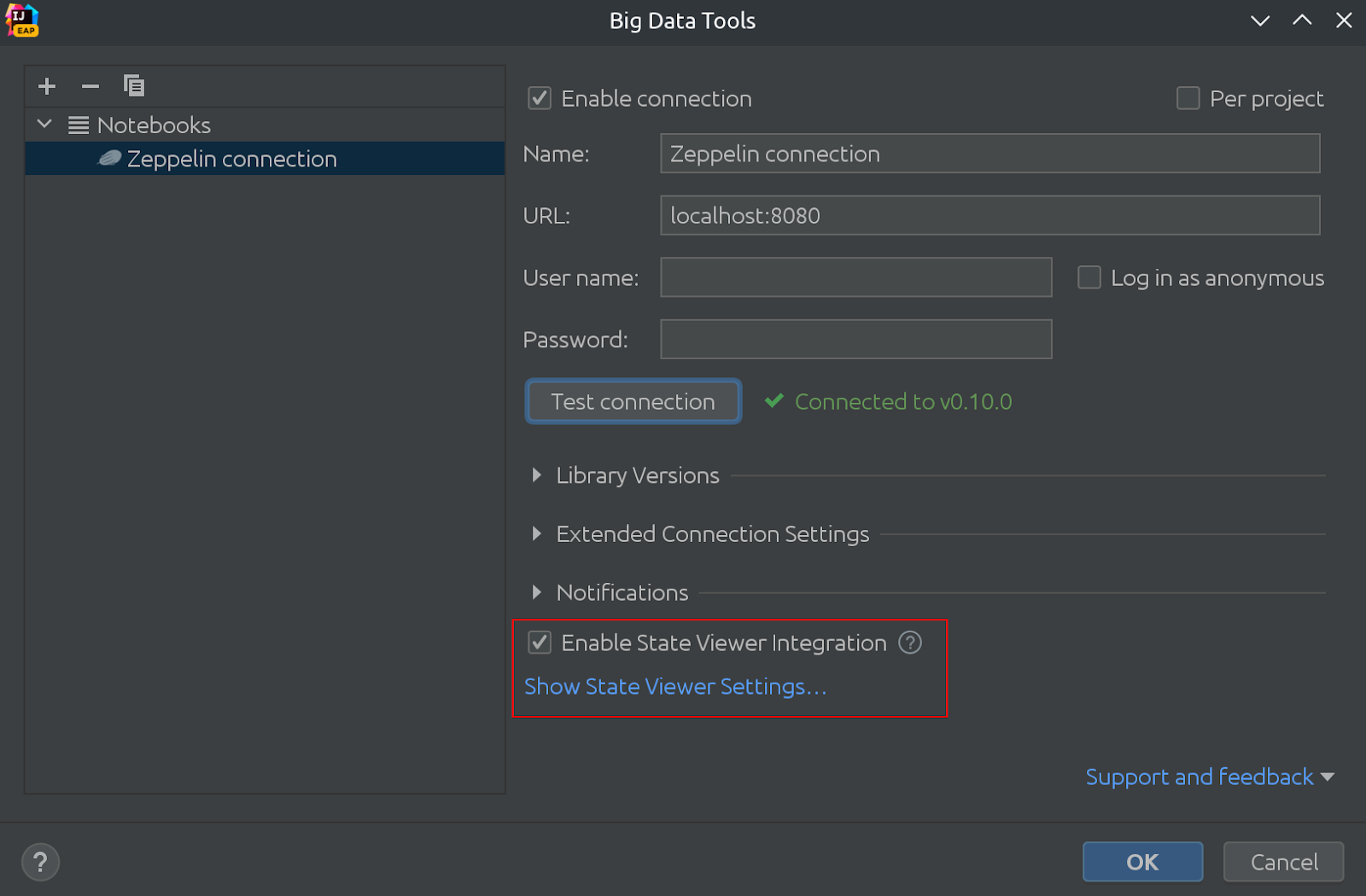
Nella stessa immagine, puoi vedere che State Viewer è ora abilitato per impostazione predefinita!
Da thick server a thick client
Il primo cambiamento significativo che abbiamo apportato è stato il passaggio da un modello "thin client" a un modello "thin server". Ciò significa che l'IDE non ha bisogno di installare nulla nell'interprete di Zeppelin. A sua volta, questo è vantaggioso quando non controlli completamente l'istanza Zeppelin.
Come funziona? Bene, questi cambiamenti sono evolutivi piuttosto che evolutivi. In precedenza, State Viewer utilizzava l'esecuzione della cella in background solo per chiamare un metodo da una libreria installata nell'interprete Zeppelin. Ora il plugin agisce in modo diverso, eseguendo la logica di raccolta dati da Zeppelin e inviandola alla finestra State Viewer.
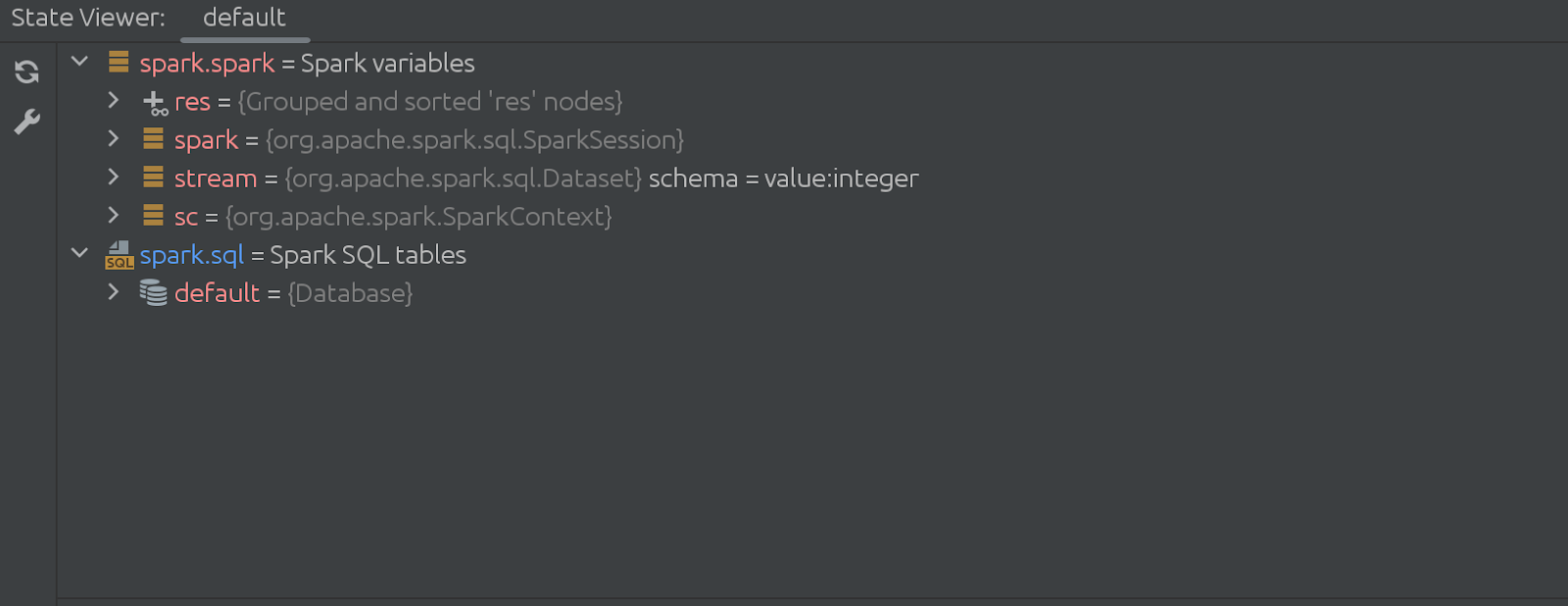
Anche il codice della cella nascosta (che scompare) è piuttosto impressionante. Inizia così:
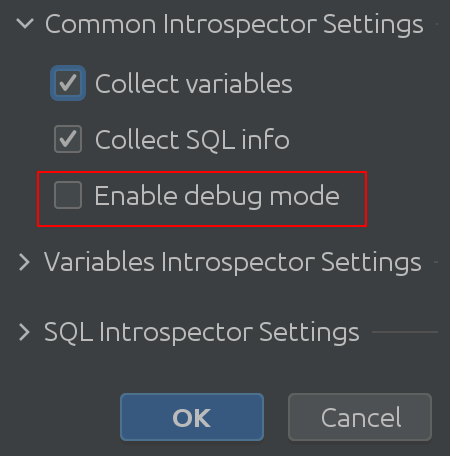
Non crederci sulla parola: controlla tu stesso il codice! Per fare ciò, abilita la "Modalità debug" nelle impostazioni:
Questo ci porta al seguente cambiamento significativo: le impostazioni del visualizzatore di stato sono state rinnovate.
Impostazioni del visualizzatore di stato
La vista completamente espansa delle impostazioni di State Viewer ha il seguente aspetto:
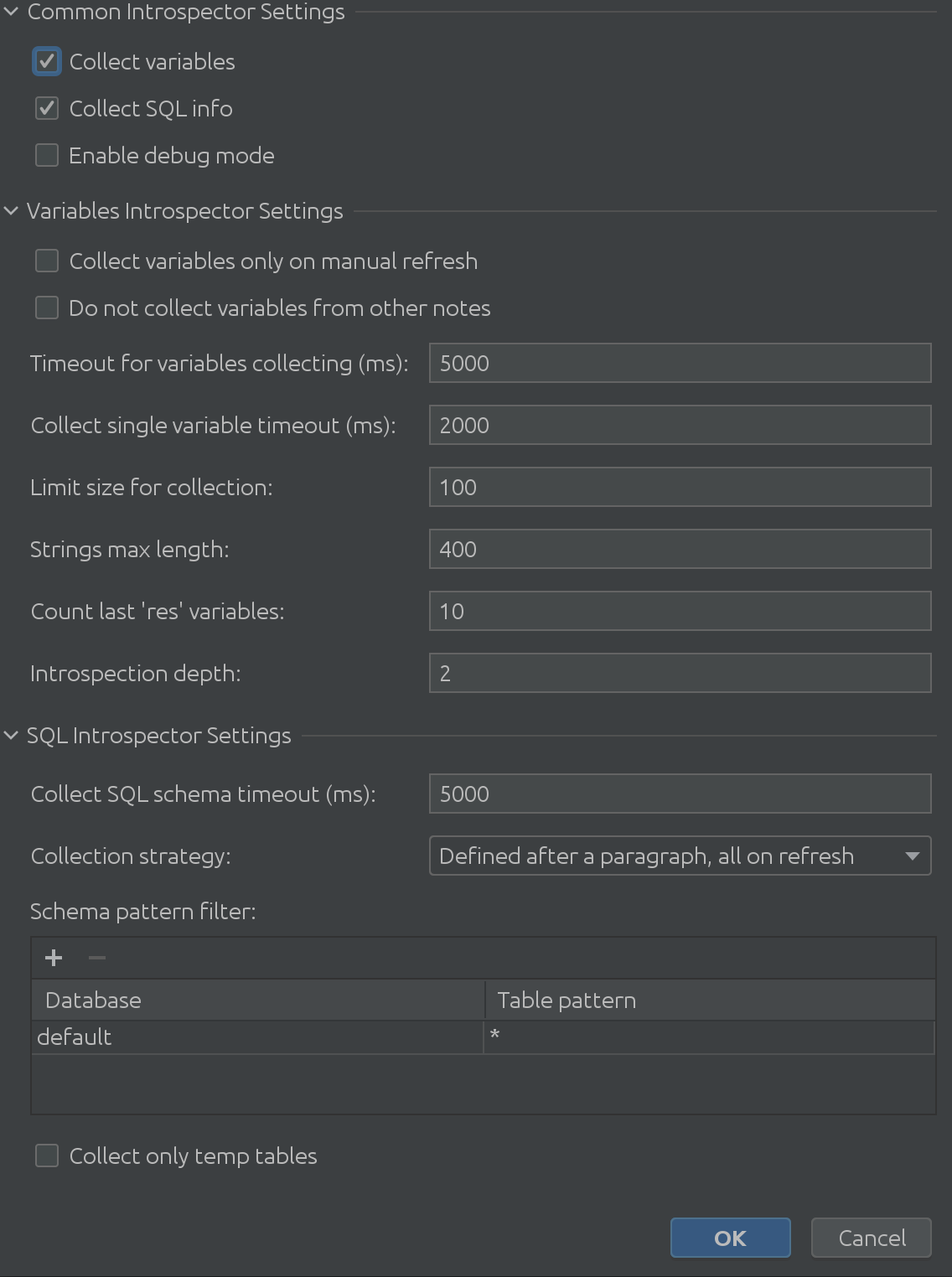
È assolutamente enorme, vero?
Come possiamo vedere nello screenshot precedente, si compone di 3 parti principali:
1. Impostazioni comuni dell'interprete
2. Impostazioni variabili di Introspector
3. Impostazioni di SQL Introspector
Si spera che il nome "Impostazioni comuni dell'interprete" sia autoesplicativo. Puoi abilitare o disabilitare la raccolta di informazioni sulle variabili da Spark SQL e ti consente di abilitare la modalità di debug. Certo, questo è molto utile per noi, gli sviluppatori di plugin, ma puoi usarlo per ottenere una comprensione più profonda del funzionamento interno del plugin. Impostazioni variabili di Introspector
Il prezioso feedback dei nostri clienti ci ha fornito una comprensione di entusiasmanti casi d'angolo durante l'introspezione delle variabili. Le impostazioni di Introspector variabili risolvono tutti i potenziali problemi che potresti incontrare. Hai bisogno di introspezionare testi più lunghi? Aumentare il limite della dimensione della stringa. Ora ci vuole più tempo per estrarli tutti? Aumenta il timeout mentre aspetti che lo Zeppelin risponda. Devi lavorare con strutture profondamente annidate? È possibile regolare con precisione la profondità massima di scavo.
Impostazioni di SQL Introspector
Non ci rendevamo nemmeno conto di quanto sarebbe stato utile SQL Introspector per alcuni dei nostri clienti! Dovevamo scoprire quanto possono essere complessi gli scenari di utilizzo su molti schemi e tabelle, il che ci ha portato alla prossima entusiasmante soluzione:
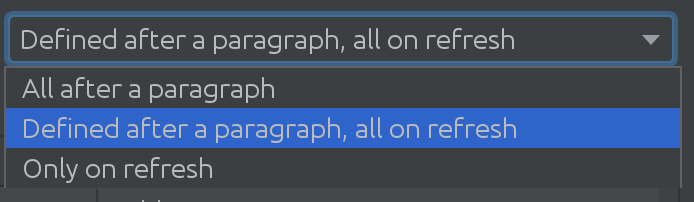
A seconda delle dimensioni del database Spark, puoi usare strategie diverse quando devi estrarre le modifiche dal database Spark. A volte i database sono così estesi che decidiamo di non eseguire il pull automatico delle modifiche.
Tutte queste modifiche ci hanno portato ad attivare Big Data Tools per impostazione predefinita in questa versione.
Abbiamo anche appreso che quando i nostri clienti lavorano con Spark, lavorano con qualcosa di più del semplice catalogo predefinito. A volte, il catalogo "predefinito" è assolutamente enorme e devono in qualche modo filtrare i dati da esso. Ecco perché abbiamo introdotto il seguente filtro in SQL Introspector:
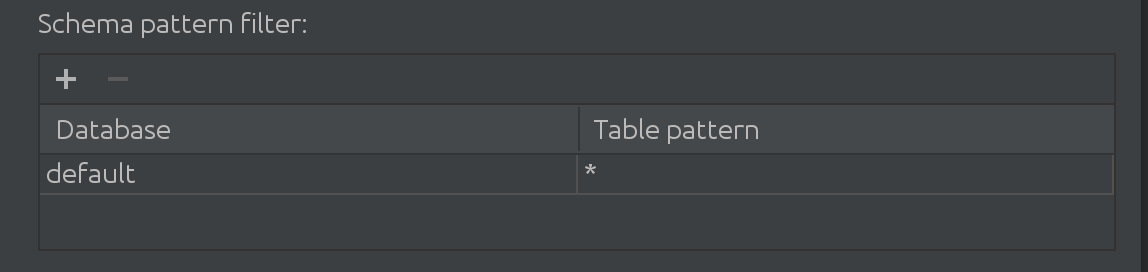
Qui puoi filtrare e aggiungere più cataloghi per cercare i dati per il completamento automatico, nonché limitare il sottoinsieme di tabelle interrogate all'interno di un catalogo.
Se utilizzi AWS Glue o Hive Metastore, potresti trovare utile anche questa casella di controllo:

È probabile che la colla della tua azienda sia incredibilmente grande e ti occorrono solo i dati che hai inserito durante la sessione.
State Viewer è ora abilitato per impostazione predefinita
Abbiamo introdotto molti miglioramenti rispetto al nostro ultimo post sul blog su questa funzione. Siamo molto grati ai nostri clienti per il loro continuo supporto e feedback continui: è stato possibile implementare molti cambiamenti grazie a loro! Ora siamo fiduciosi che Big Data Tools sia abbastanza stabile e flessibile da consentire al nostro pubblico generale di poterlo utilizzare continuamente per questi motivi:
1. Non richiede più modifiche in Zeppelin.
2. Ti consente di mettere a punto l'introspezione delle variabili in base al tuo caso d'uso.
3. Ti consente di ottimizzare l'introspezione SQL in base al contesto e alla complessità delle tue attività.
4. La meccanica delle celle nascoste è stata migliorata.
5. Abbiamo un metodo per consentire ai nostri utenti di verificare e comprendere a fondo la funzionalità del plug-in. ha fatto un passo in più per consentire ai nostri clienti di "controllarci" e assicurarsi che stiamo facendo solo quello che diciamo di fare, e non di più.
Se sei interessato a provare Big Data Tools, puoi trovare facilmente il plug-in qui .
 Email
Email