長いこと覚えてる私たちが紹介した時ですビッグデータツールプラグインの機能が呼び出されますZToolsそれは、zeppelinノートブックの変数の現在の状態を表示することができますか?ほぼ1年前にztoolsの実装に大幅な変更を加えたことを覚えていますか?
この部分について大きな発表をするのが私たちの伝統ですビッグデータ道具そして今日、私たちはいくつかのエキサイティングな変更を発表します。自分で試してみたい人は、プラグインへのリンクを貼っておく。
新しい名前
最も重要なのは、この機能が「state viewer」と呼ばれるようになったことです。state viewerはzeppelinだけでなく、他のノートブックにも変数表示を実装できるため、名前を変更することにしました。他にもいくつかの名前が考えられていましたが、選択は容易ではありませんでした。
以下は、その様子だ:
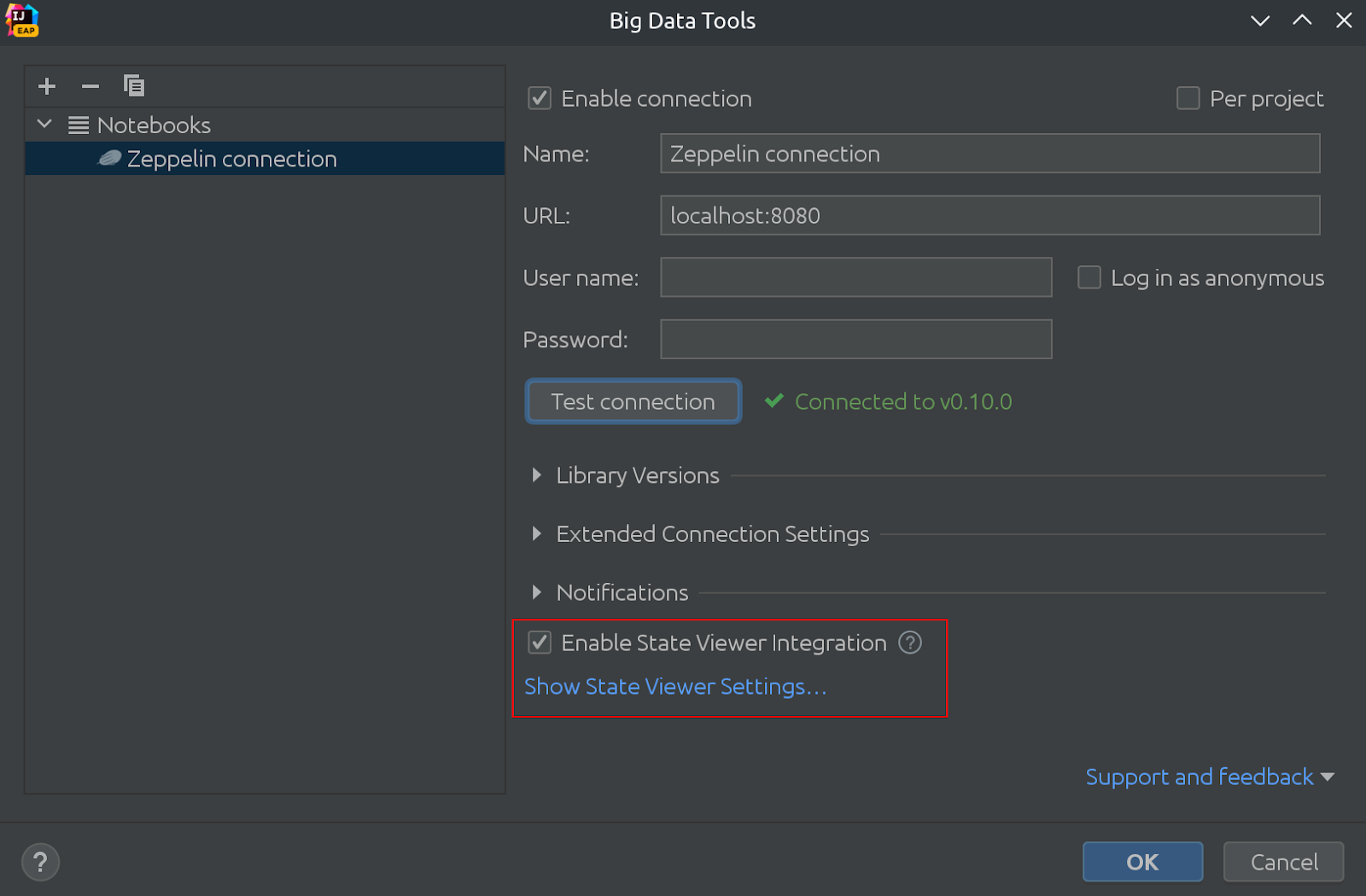
同じ図で、state viewerがデフォルトで有効になっていることがわかります。
厚いサーバーから厚いクライアントへ
最初に行った重要な変更は、「シンクライアント」から「シンサーバー」モデルへの移行です。これは、ideがzeppelinのインタプリタに何もインストールする必要がないことを意味します。これは、ツェッペリンのインスタンスを完全に制御できない場合に役立ちます。
それはどのように機能しますか?これらの変化は進化的というよりは進化的ですこれまでstate viewerは、バックグラウンドセル実行を使用して、zeppelinインタプリタにインストールしたライブラリからメソッドを呼び出すだけでした。プラグインの動作が変更され、zeppelinからデータ収集ロジックを実行してstate viewerウィンドウに送信するようになりました。
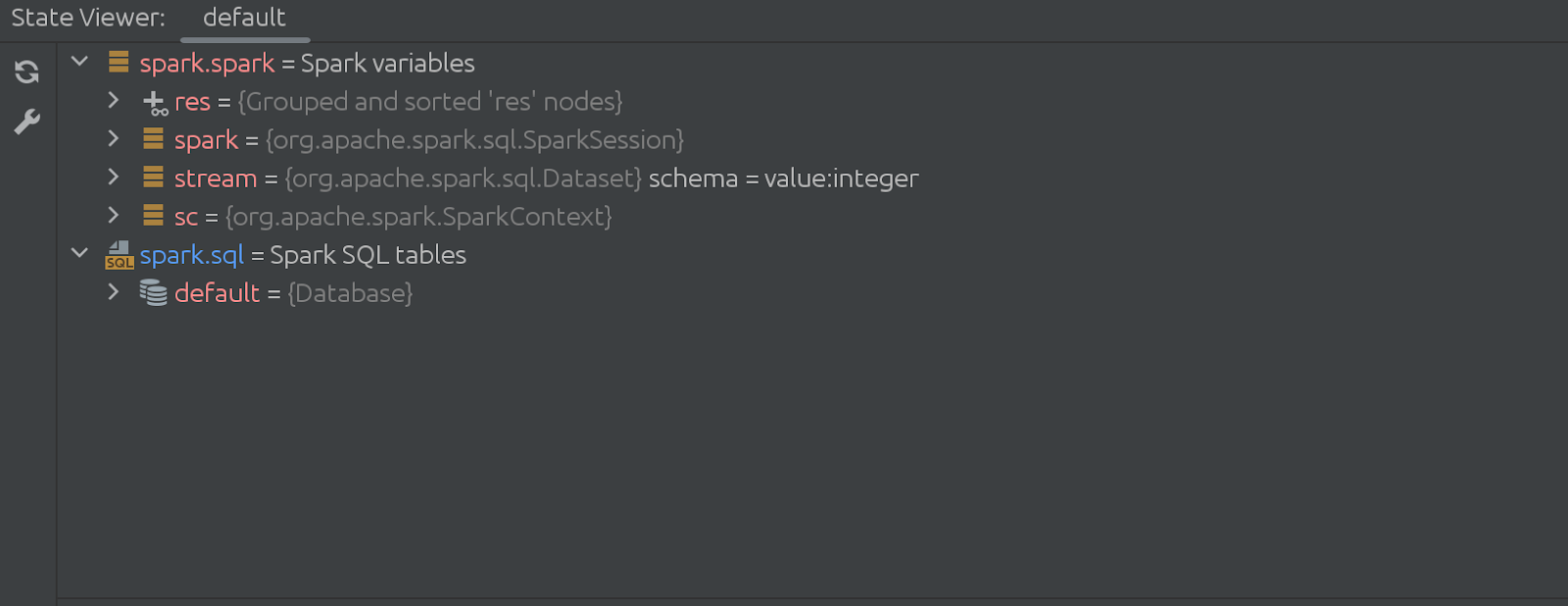
隠された(消える)セルのコードもかなり印象的です。このように始まります
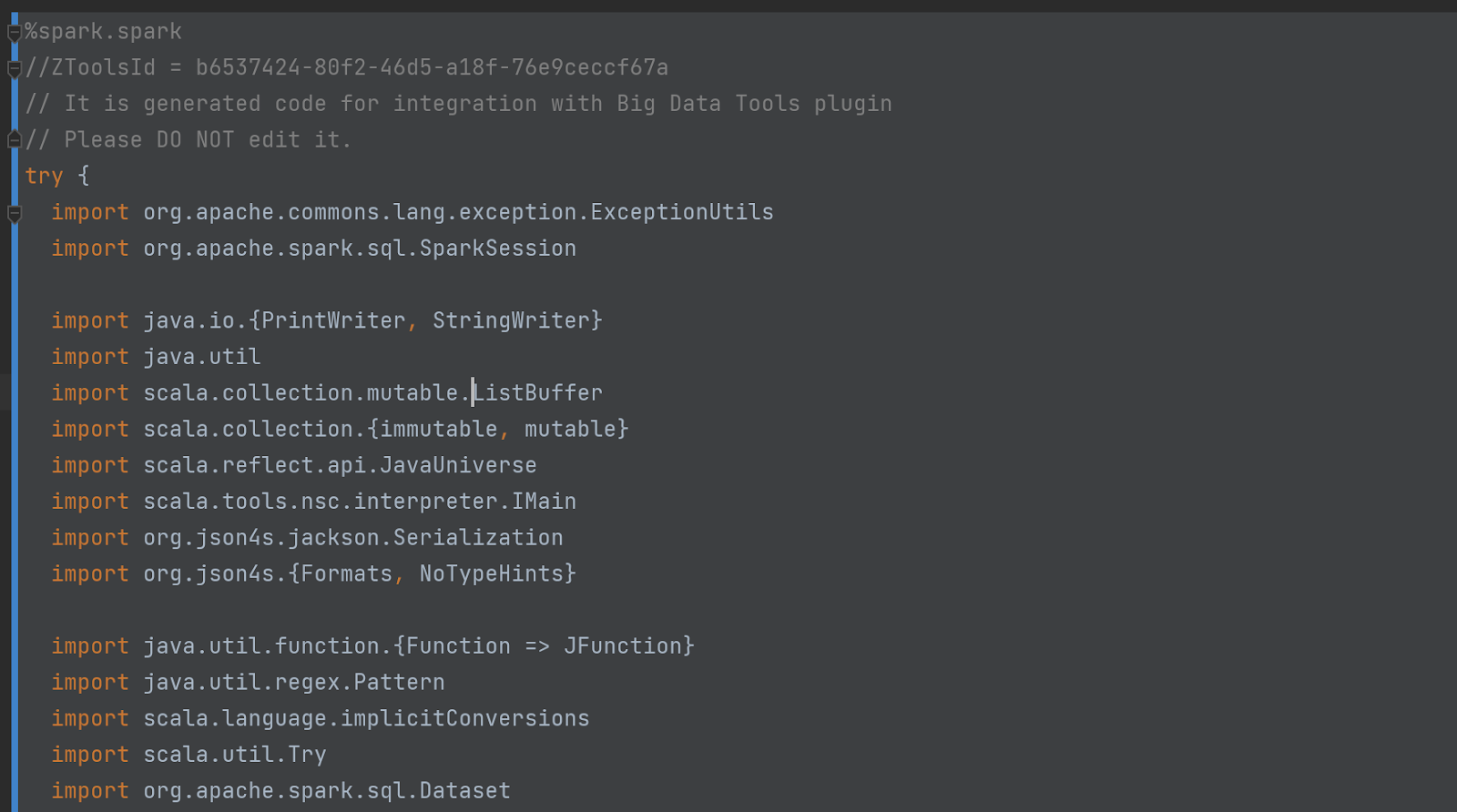
私たちの言葉を信じないでください-自分でコードをチェックしてください!これを行うには、設定で「デバッグモード」を有効にします。
これにより、以下の重要な変更が行われました。state viewerの設定が改良されました。
国家視聴者設定
state viewer設定の完全展開ビューは次のようになります。
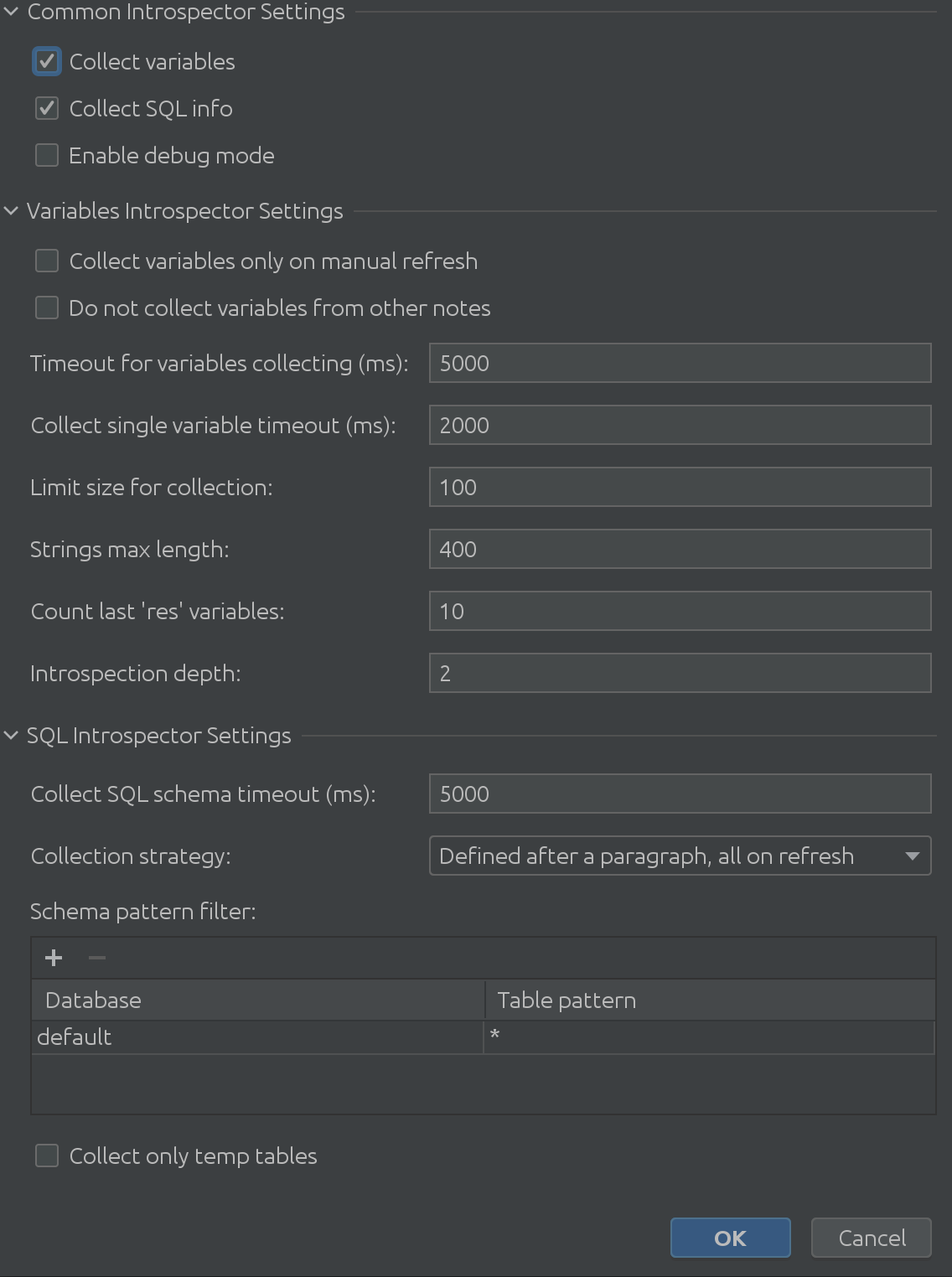
絶対に巨大ですよね?
前のスクリーンショットで見たように、3つの主要な部分から構成されています。
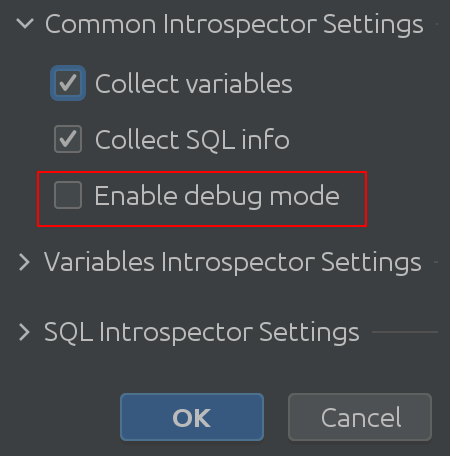
1. 共通通訳設定
2. 可変Introspector設定
3. SQL Introspector設定
うまくいけば、" common interpreter settings "という名前は自明です。spark sqlから変数に関する情報の収集を有効または無効にでき、デバッグモードを有効にできます。確かにこれはプラグイン開発者である私たちにとって最も便利ですが、プラグインの内部動作をより深く理解するために使用することができます。可変Introspector設定
お客様からの貴重なフィードバックにより、変数を検討する際の刺激的なコーナーケースを理解できました。変数のイントロスペクター設定は、発生する可能性のあるすべての潜在的な問題に対処します。長いテキストを反省する必要がありますか?文字列サイズの上限を増やします。今それはそれらをすべて抽出するのに時間がかかりますか?ツェッペリンが応答するまでのタイムアウト時間を増やしました。深く入れ子になった構造を扱う必要があるでしょうか?最大掘る深さを微調整できます。
SQL Introspector設定
私たちは、一部のお客様にとってsql introspectorがどれほど有用であるかを理解していませんでした。多くのスキーマやテーブルにまたがる複雑な使用シナリオを見つける必要がありました。その結果、次のエキサイティングなソリューションにつながりました。
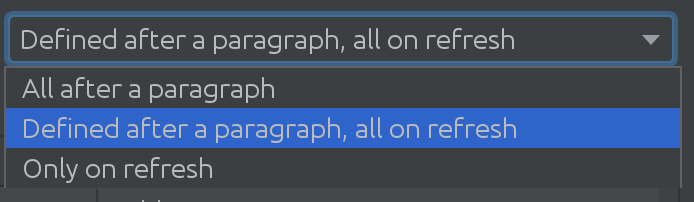
sparkデータベースのサイズに応じて、sparkデータベースから変更を取得する必要がある場合には、さまざまな戦略を使用できます。時々データベース范囲が広く我々は全身で自動的に変化力ないと決めた
これらすべての変更により、今回のリリースではビッグデータツールがデフォルトでオンになりました。
また、お客様がsparkを使用する際には、デフォルトのカタログだけではないこともわかりました。場合によっては、"デフォルト"カタログが非常に大きく、何らかの方法でデータをフィルタリングする必要があります。そのため、sqlイントロスペクターに次のフィルタを導入しました。
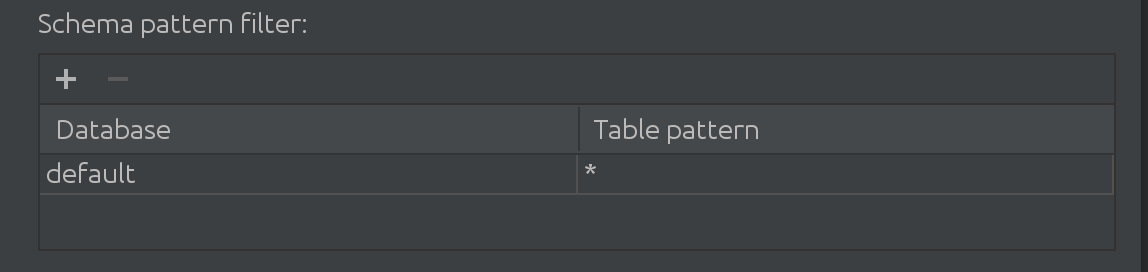
ここでは、自動補完のためにデータを検索するカタログをフィルターおよび追加し、カタログ内のクエリされたテーブルのサブセットを制限することができます。
aws glueまたはhive metastoreを使用している場合は、このチェックボックスも便利です。

あなたの会社の接着剤は信じられないほど大きくなる可能性があり、必要なのはセッション中にそこに置くデータだけです。
state viewerをデフォルトで有効にするようにした
この機能についての前回のブログ記事以来、多くの改善点を紹介してきました。お客様の継続的なサポートと継続的なフィードバックに感謝しています。ビッグデータツールは、一般ユーザーが次のような理由で継続的に使用できるように、十分に安定して柔軟であると確信しています。
1. ゼッペリンを変更する必要はなくなりました。
2. これにより、使用事例に合わせて変数のイントロスペクションを微調整することができます。
3. タスクのコンテキストと複雑さに応じてsqlのイントロスペクションを調整できます。
4. 隠れた細胞の仕組みが改善されました。
5. ユーザーがプラグインの機能を確認し、深く理解するためのメソッドがあります。お客様が「チェックアウト」できるようにするために、私たちがやっていると言ったことだけを実行していて、それ以上実行していないことを確認できるようにするために、さらなる一歩を踏み出しました。
ビッグデータツールを試してみたい人は、プラグインを簡単に見つけることができますここ。
 メール
メール