오래 전에 Zeppelin 노트북에서 변수의 현재 상태를 볼 수 있는 ZTools 라는 Big Data Tools 플러그인의 기능을 도입했던 때를 기억하십니까? 거의 1년 전에 ZTools 구현을 크게 변경한 것을 기억하십니까?
빅 데이터 도구 의 이 부분에 대해 매년 큰 발표를 하는 것이 우리의 전통이며, 오늘 우리는 여러 가지 흥미로운 변경 사항을 발표합니다. 직접 확인하고 싶다면 플러그인에 대한 링크는 다음과 같습니다.
새 이름
가장 중요한 것은 이 기능을 이제 "상태 뷰어"라고 합니다. State Viewer는 Zeppelin뿐만 아니라 다른 노트북에서도 변수 보기를 구현할 수 있기 때문에 이름을 변경하기로 결정했습니다. 몇 가지 다른 이름을 고려하고 있었고 선택이 쉽지 않았습니다.
다음과 같이 표시됩니다.
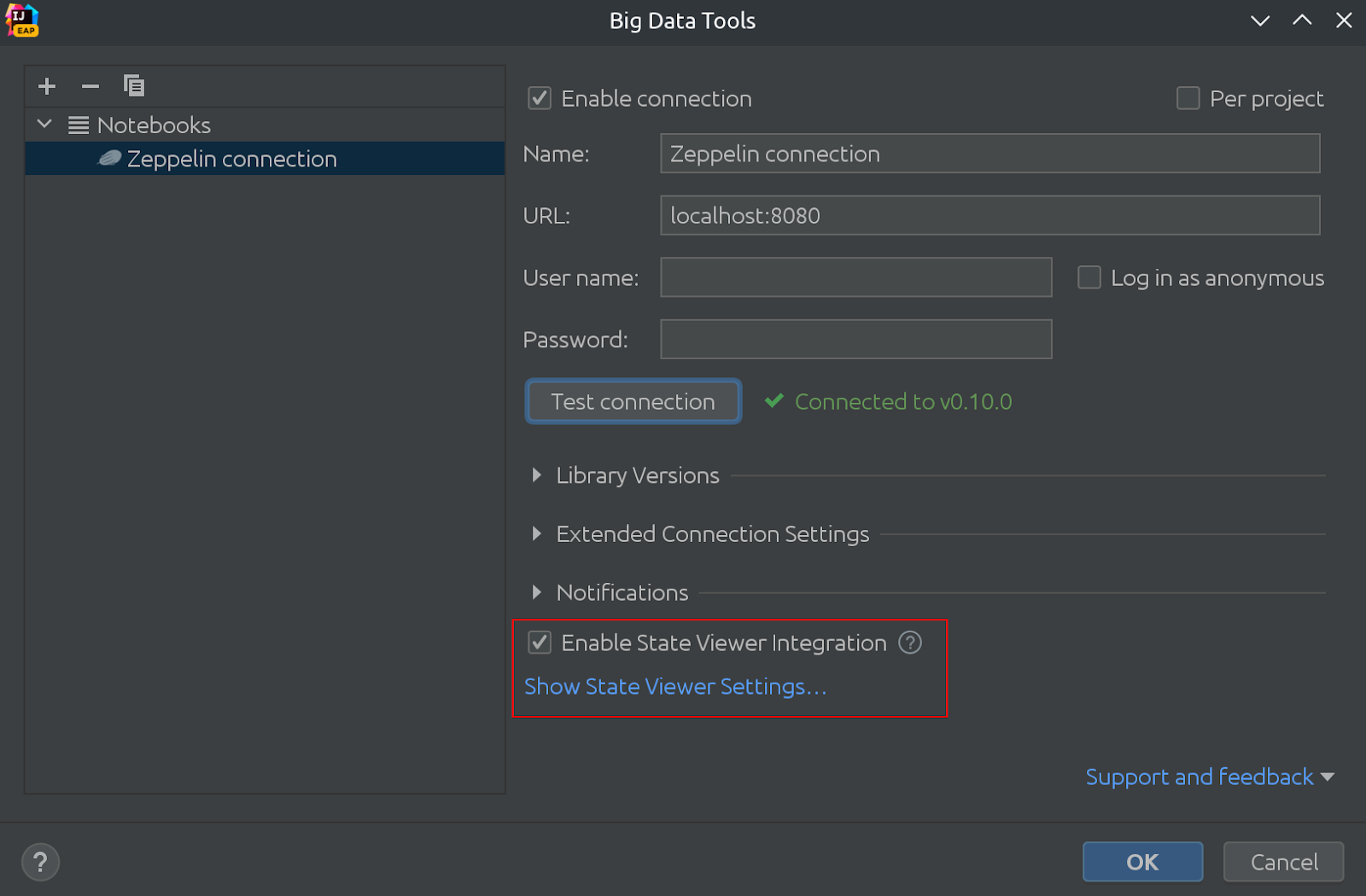
같은 그림에서 State Viewer가 기본적으로 활성화되어 있음을 알 수 있습니다!
씩 서버에서 씩 클라이언트로
우리가 만든 첫 번째 중요한 변화는 "씬 클라이언트"에서 "씬 서버" 모델로의 이동이었습니다. 즉, IDE는 Zeppelin의 인터프리터에 아무 것도 설치할 필요가 없습니다. 결과적으로 이것은 Zeppelin 인스턴스를 완전히 제어하지 못할 때 유용합니다.
어떻게 작동합니까? 음, 이러한 변화는 진화적이라기보다는 진화적입니다. 이전에는 State Viewer가 배경 셀 실행을 사용하여 Zeppelin 인터프리터에 설치한 라이브러리에서 메서드를 호출했습니다. 이제 플러그인은 다르게 작동하여 Zeppelin에서 데이터 수집 로직을 실행하고 이를 State Viewer 창으로 보냅니다.
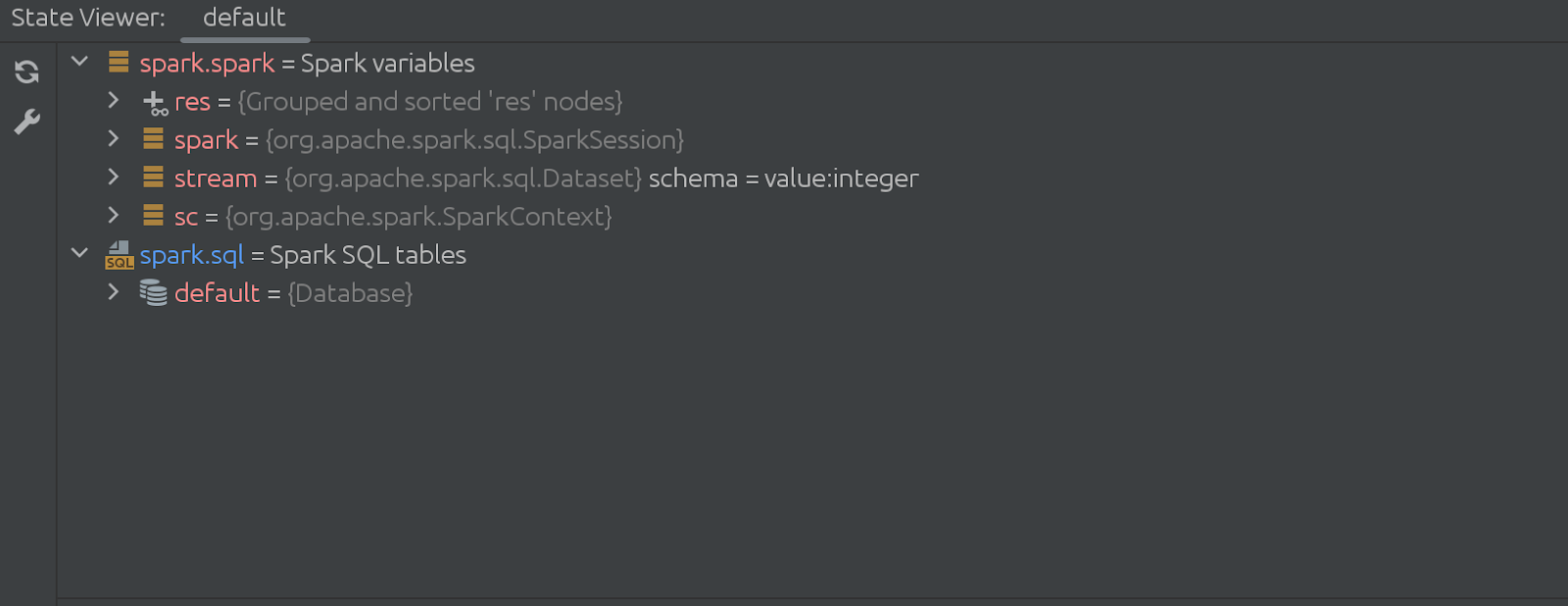
숨은(사라지는) 세포의 코드도 상당히 인상적이다. 다음과 같이 시작합니다.
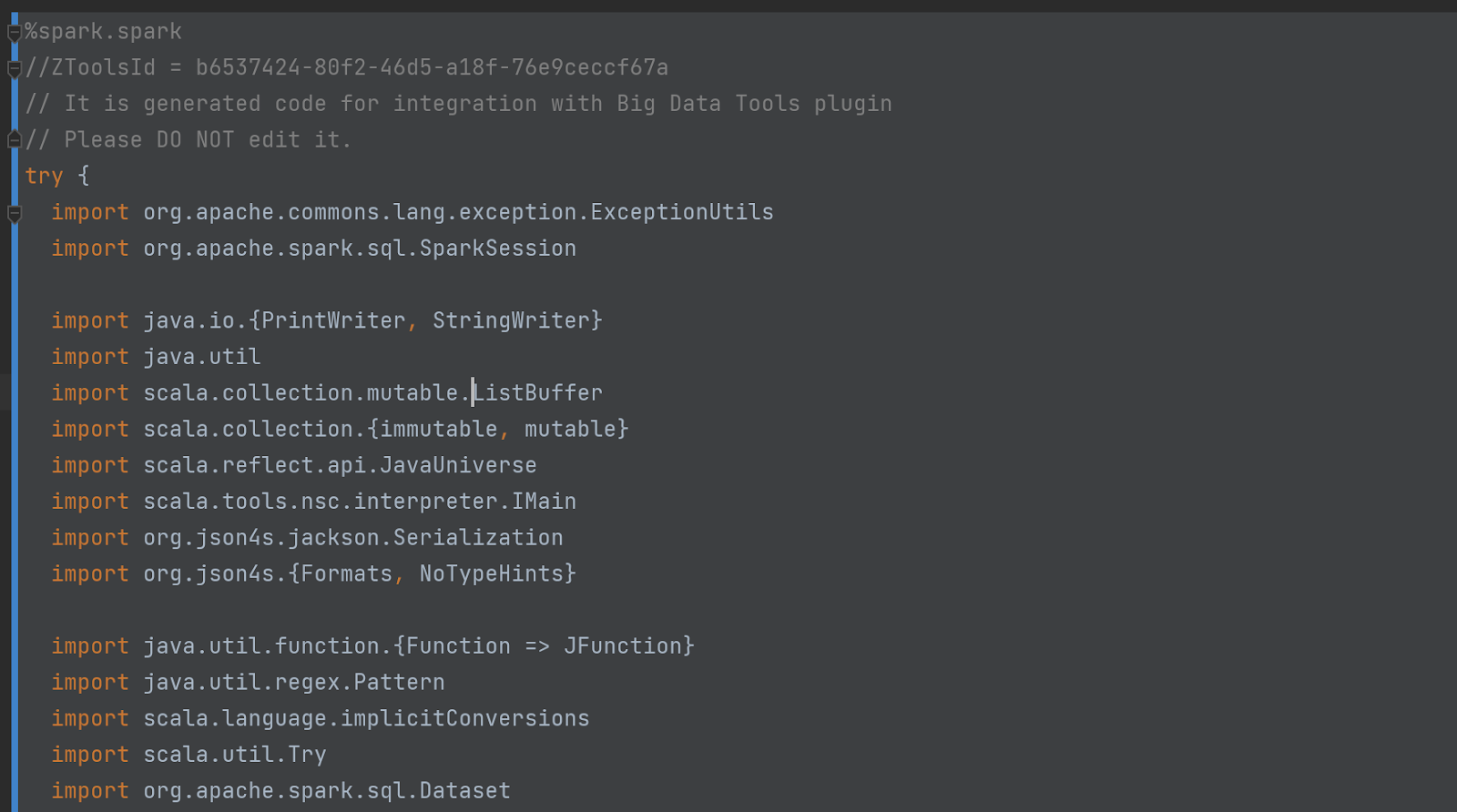
우리의 말을 믿지 마세요. 직접 코드를 확인하세요! 이렇게 하려면 설정에서 "디버그 모드"를 활성화하십시오.
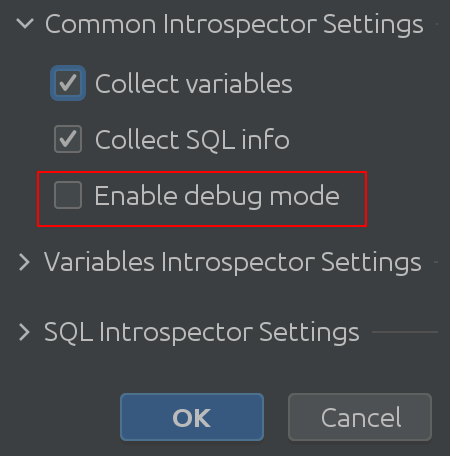
이로 인해 다음과 같은 중요한 변경 사항이 발생했습니다. 상태 뷰어 설정이 개선되었습니다.
상태 뷰어 설정
State Viewer 설정의 완전히 확장된 보기는 다음과 같습니다.
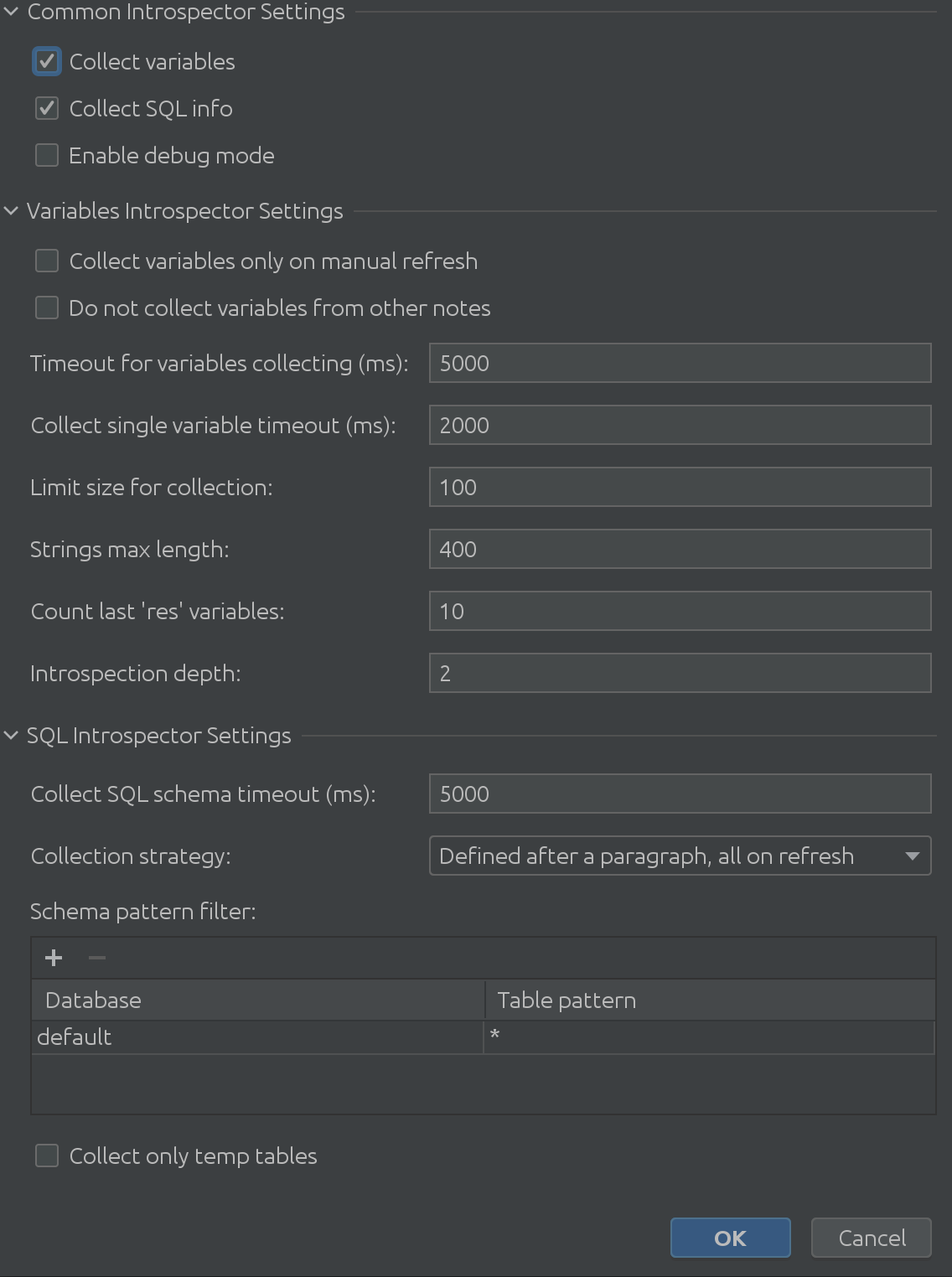
완전 방대하죠?
이전 스크린샷에서 볼 수 있듯이 3개의 주요 부분으로 구성됩니다.
1. 공통 통역사 설정
2. 가변 인트로스펙터 설정
3. SQL Introspector 설정
바라건대 "Common Interpreter Settings"라는 이름은 자명합니다. Spark SQL에서 변수에 대한 정보 수집을 활성화 또는 비활성화할 수 있으며 디버그 모드를 활성화할 수 있습니다. 틀림없이 이것은 플러그인 개발자인 우리에게 가장 유용하지만 플러그인의 내부 작동을 더 깊이 이해하는 데 사용할 수 있습니다.Variable Introspector Settings
고객의 소중한 피드백을 통해 변수를 검사할 때 흥미로운 코너 케이스를 이해할 수 있었습니다. Variable Introspector Settings는 발생할 수 있는 모든 잠재적인 문제를 해결합니다. 더 긴 텍스트를 성찰해야 합니까? 문자열 크기 제한을 늘립니다. 이제 모두 추출하는 데 시간이 더 걸리나요? Zeppelin의 응답을 기다리는 동안 제한 시간을 늘립니다. 깊게 중첩된 구조로 작업해야 합니까? 최대 굴착 깊이를 미세 조정할 수 있습니다.
SQL Introspector 설정
SQL Introspector가 일부 고객에게 얼마나 유용한지조차 깨닫지 못했습니다! 많은 스키마와 테이블에서 사용 시나리오가 얼마나 복잡한지 알아내야 했고, 다음 흥미로운 솔루션을 찾았습니다.
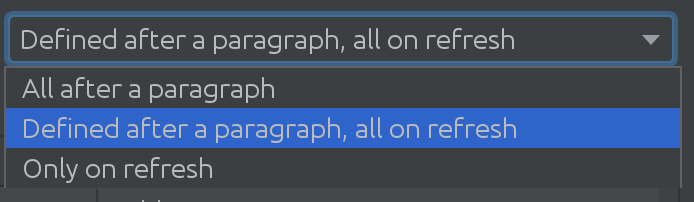
Spark 데이터베이스의 크기에 따라 Spark 데이터베이스에서 변경 사항을 가져와야 할 때 다양한 전략을 사용할 수 있습니다. 때로는 데이터베이스가 너무 광범위하여 변경 사항을 자동으로 가져오지 않기로 결정하기도 합니다.
이러한 모든 변경 사항으로 인해 이 릴리스에서는 기본적으로 Big Data Tools를 사용하도록 설정했습니다.
또한 고객이 Spark로 작업할 때 기본 카탈로그 이상으로 작업한다는 사실도 알게 되었습니다. 때때로 "기본" 카탈로그는 절대적으로 방대하며 어떻게든 카탈로그에서 데이터를 필터링해야 합니다. 그래서 SQL Introspector에 다음 필터를 도입했습니다.
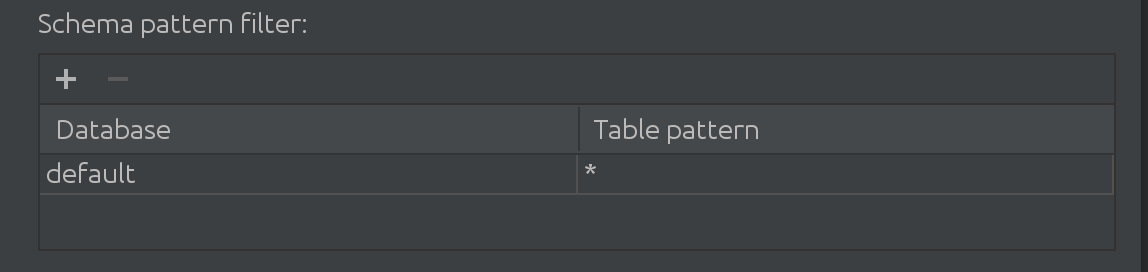
여기에서 더 많은 카탈로그를 필터링하고 추가하여 자동 완성을 위한 데이터를 찾을 수 있을 뿐만 아니라 카탈로그 내에서 쿼리된 테이블의 하위 집합을 제한할 수 있습니다.
AWS Glue 또는 Hive Metastore를 사용하는 경우 이 확인란도 유용할 수 있습니다.

회사의 Glue는 엄청나게 클 가능성이 높으며 세션 중에 입력한 데이터만 필요합니다.
이제 상태 뷰어가 기본적으로 활성화됩니다.
이 기능에 대한 지난 블로그 게시물 이후 많은 개선 사항을 소개했습니다. 고객 여러분의 지속적인 지원과 지속적인 피드백에 매우 감사드립니다. 고객 덕분에 많은 변화를 구현할 수 있었습니다! 우리는 이제 Big Data Tools가 다음과 같은 이유로 일반 청중이 지속적으로 사용할 수 있을 만큼 충분히 안정적이고 유연하다고 확신합니다.
1. 더 이상 Zeppelin에서 변경할 필요가 없습니다.
2. 사용 사례에 맞게 변수 검사를 미세 조정할 수 있습니다.
3. 작업의 컨텍스트 및 복잡성에 따라 SQL 검사를 조정할 수 있습니다.
4. 히든 셀의 메커니즘이 개선되었습니다.
5. 사용자가 플러그인의 기능을 확인하고 깊이 이해할 수 있는 방법이 있습니다. 고객이 "우리를 확인"하고 우리가 하고 있는 일만 하고 있는지 확인하고 그 이상은 할 수 없도록 추가 조치를 취했습니다.
Big Data Tools 사용에 관심이 있다면 여기에서 플러그인을 쉽게 찾을 수 있습니다.
 이 메일
이 메일