Você se lembra há muito tempo quando introduzimos um recurso no plug-in Big Data Tools chamado ZTools que permite visualizar o estado atual das variáveis em um notebook Zeppelin? Você se lembra que fizemos mudanças significativas na implementação do ZTools há quase um ano?
É nossa tradição fazer grandes anúncios sobre esta parte das ferramentas de Big Data anualmente, e hoje estamos anunciando várias mudanças interessantes. Se preferir verificá-los você mesmo, aqui está o link para o plug-in:
Novo nome
Mais importante ainda, esse recurso agora é chamado de “Visualizador de estado”. Decidimos mudar o nome porque o State Viewer também pode implementar visualização variável para outros notebooks, não apenas para o Zeppelin. Havia alguns outros nomes sendo considerados, e a escolha não foi fácil.
Aqui está como parece:
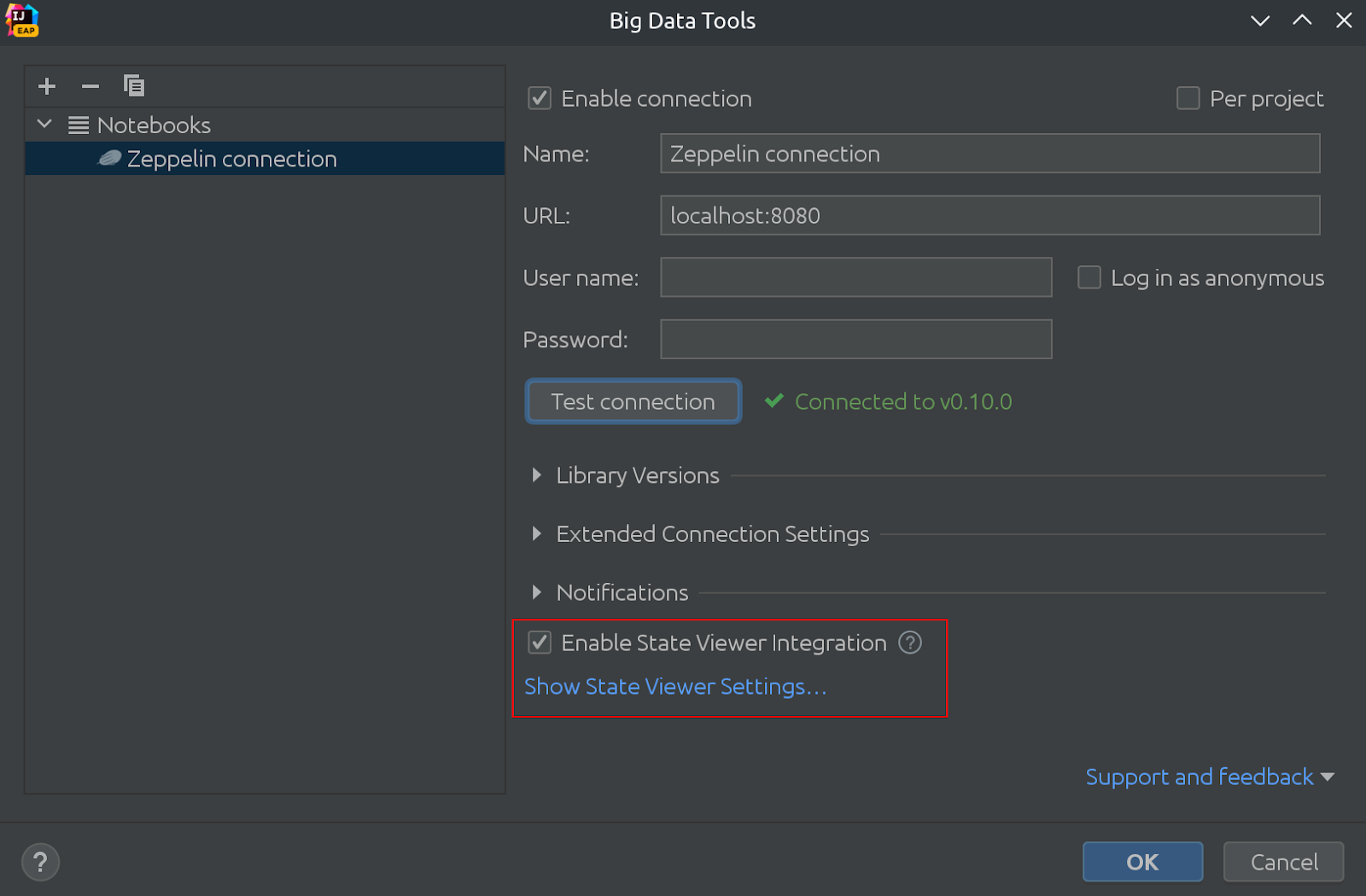
Na mesma foto, você pode ver que o State Viewer agora está habilitado por padrão!
Servidor grosso para cliente grosso
A primeira mudança significativa que fizemos foi a mudança de um modelo de “thin client” para um modelo de “thin server”. Isso significa que o IDE não precisa instalar nada no interpretador do Zeppelin. Por sua vez, isso é benéfico quando você não controla totalmente a instância do Zeppelin.
Como funciona? Bem, essas mudanças são evolutivas e não evolutivas. Anteriormente, o State Viewer usava a execução da célula em segundo plano apenas para chamar um método de uma biblioteca que instalamos no interpretador Zeppelin. Agora o plugin age de forma diferente, executando a lógica de coleta de dados do Zeppelin e enviando-a para a janela State Viewer.
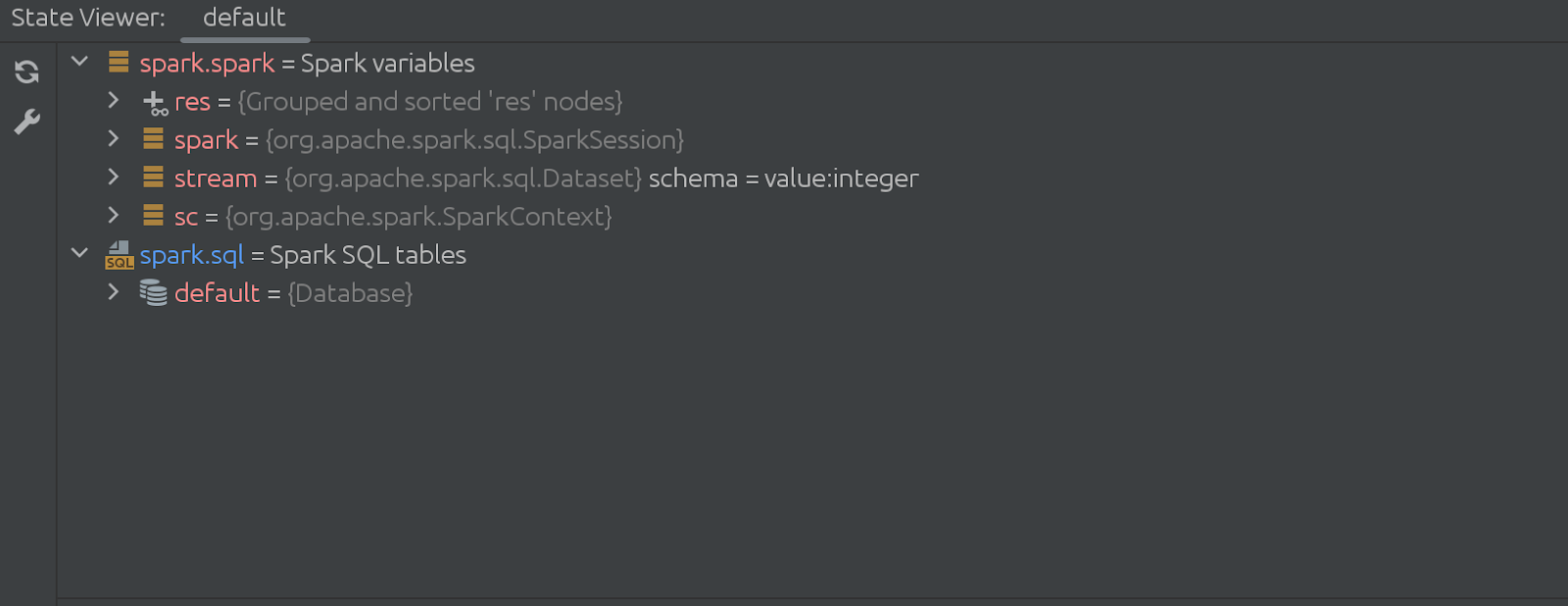
O código da célula oculta (desaparecendo) também é bastante impressionante. Começa assim:
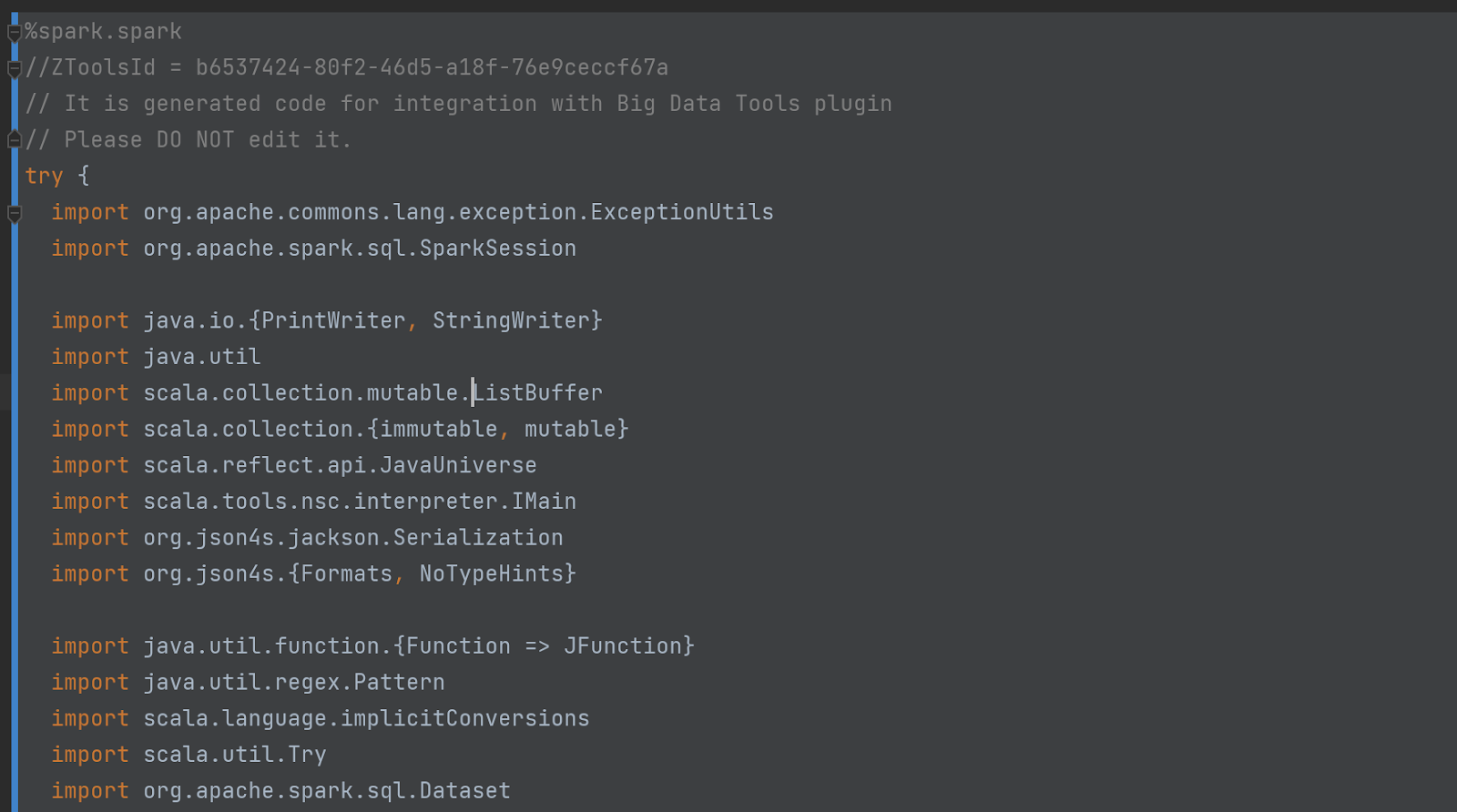
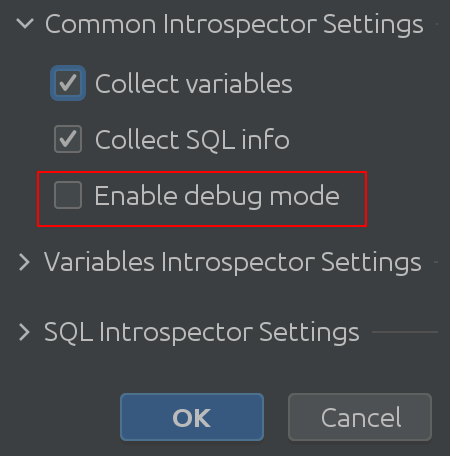
Não acredite apenas em nossa palavra – confira você mesmo o código! Para fazer isso, ative o “Modo de depuração” nas configurações:
Isso nos leva à seguinte mudança significativa: as configurações do visualizador de estado foram reformuladas.
Configurações do visualizador de estado
A exibição totalmente expandida das configurações do Visualizador de estado se parece com isto:
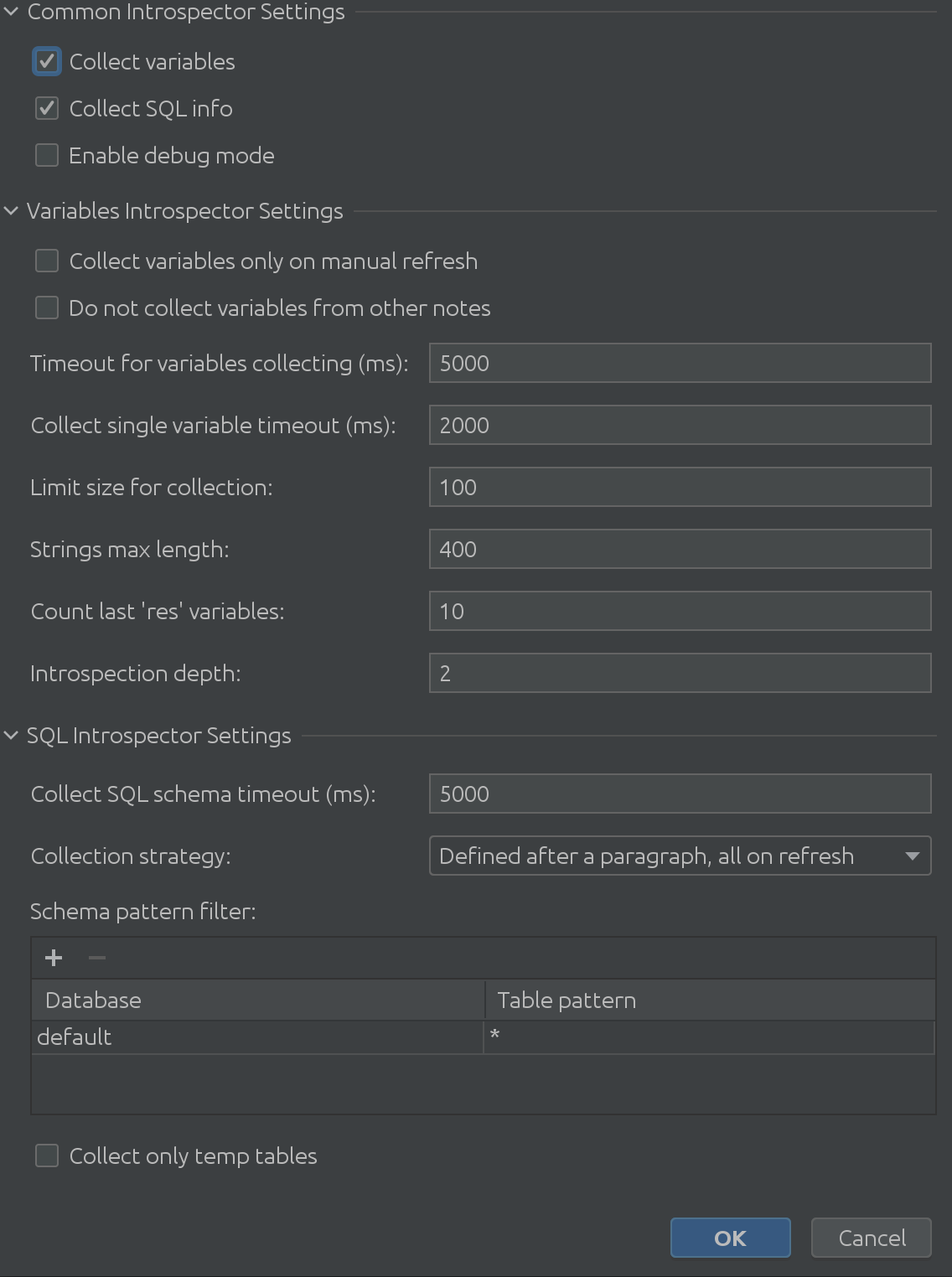
É absolutamente enorme, certo?
Como podemos ver na captura de tela anterior, ele consiste em 3 partes principais:
1. Configurações comuns do intérprete
2. Configurações variáveis do Introspector
3. Configurações do SQL Introspector
Esperançosamente, o nome “Common Interpreter Settings” é autoexplicativo. Você pode ativar ou desativar a coleta de informações sobre variáveis do Spark SQL e permite ativar o modo de depuração. Reconhecidamente, isso é mais útil para nós, os desenvolvedores do plug-in, mas você pode usá-lo para obter uma compreensão mais profunda do funcionamento interno do plug-in.Variable Introspector Settings
O feedback valioso de nossos clientes nos deu uma compreensão de casos interessantes ao analisar variáveis. Variable Introspector Settings aborda todos os possíveis problemas que você pode encontrar. Precisa introspeccionar textos mais longos? Aumente o limite do tamanho da String. Agora leva mais tempo para extrair todos eles? Aumente o tempo limite enquanto aguarda a resposta do Zeppelin. Tem que trabalhar com estruturas profundamente aninhadas? Você pode ajustar a profundidade máxima de escavação.
Configurações do SQL Introspector
Nem imaginávamos como o SQL Introspector seria útil para alguns de nossos clientes! Precisávamos descobrir como os cenários de uso complexos podem ser em vários esquemas e tabelas, o que nos levou à próxima solução empolgante:
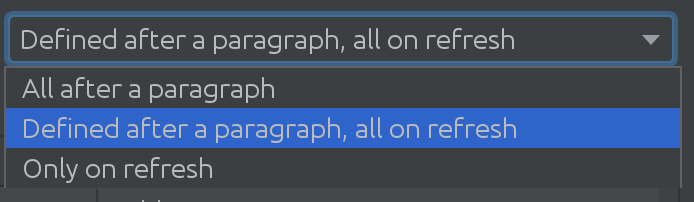
Dependendo do tamanho do seu banco de dados Spark, você pode usar estratégias diferentes quando precisar extrair alterações do banco de dados Spark. Às vezes, os bancos de dados são tão extensos que decidimos não puxar as alterações automaticamente.
Todas essas mudanças nos levaram a ativar o Big Data Tools por padrão nesta versão.
Também aprendemos que quando nossos clientes trabalham com o Spark, eles trabalham com mais do que apenas o catálogo padrão. Às vezes, o catálogo “padrão” é absolutamente enorme e eles precisam filtrar os dados dele de alguma forma. É por isso que introduzimos o seguinte filtro no SQL Introspector:
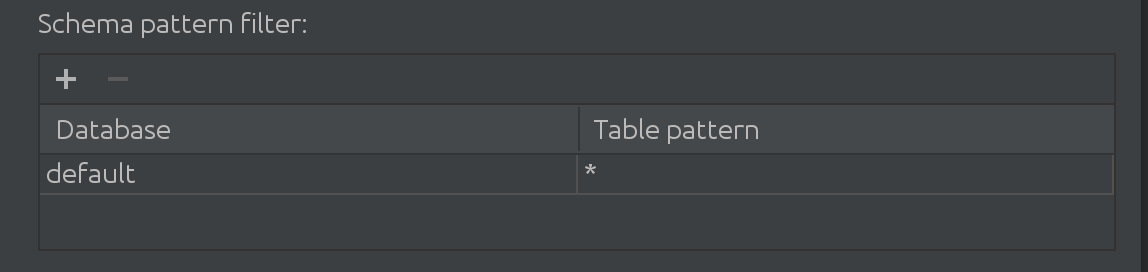
Aqui você pode filtrar e adicionar mais catálogos para procurar dados para preenchimento automático, bem como limitar o subconjunto de tabelas consultadas dentro de um catálogo.
Se você usa AWS Glue ou Hive Metastore, também pode achar esta caixa de seleção útil:

O Glue da sua empresa provavelmente é incrivelmente grande e você só precisa dos dados que colocou lá durante a sessão.
O visualizador de estado agora está ativado por padrão
Introduzimos muitas melhorias desde nossa última postagem no blog sobre esse recurso. Somos muito gratos aos nossos clientes por seu suporte contínuo e feedback contínuo – foi possível implementar muitas mudanças por causa deles! Agora estamos confiantes de que o Big Data Tools é estável e flexível o suficiente para que nosso público em geral possa usá-lo continuamente por estes motivos:
1. Não requer mais alterações no Zeppelin.
2. Ele permite que você ajuste a introspecção variável para o seu caso de uso.
3. Permite ajustar a introspecção SQL de acordo com o contexto e a complexidade de suas tarefas.
4. A mecânica das células ocultas foi aprimorada.
5. Temos um método para que nossos usuários verifiquem e entendam profundamente a funcionalidade do plug-in. deu um passo extra para permitir que nossos clientes “nos verifiquem” e certifiquem-se de que estamos fazendo apenas o que dizemos que estamos fazendo, e nada mais.
Se você estiver interessado em experimentar o Big Data Tools, poderá encontrar facilmente o plug-in aqui .
 Email
Email