Ты помнишь что-нибудь Когда мы познакомились Функция в плагине Big Data Tools называется Инструменты и инструменты Это позволяет просматривать текущее состояние переменных в записной книжке Zeppelin? Помните, что почти год назад мы внесли значительные изменения в реализацию ZTools?
Это наша традиция делать большие объявления об этой части Инструменты больших данных Каждый год, и сегодня мы объявляем о нескольких захватывающих изменениях. Если вы хотите просто проверить их самостоятельно, вот ссылка на плагин:
Новое имя и фамилия
Самое главное, эта функция теперь называется "State Viewer".Мы решили изменить имя, потому что State Viewer может осуществлять просмотр переменных и для других ноутбуков, а не только для Zeppelin.Были рассмотрены несколько других имен, и выбор был нелегким.
Вот как это выглядит:
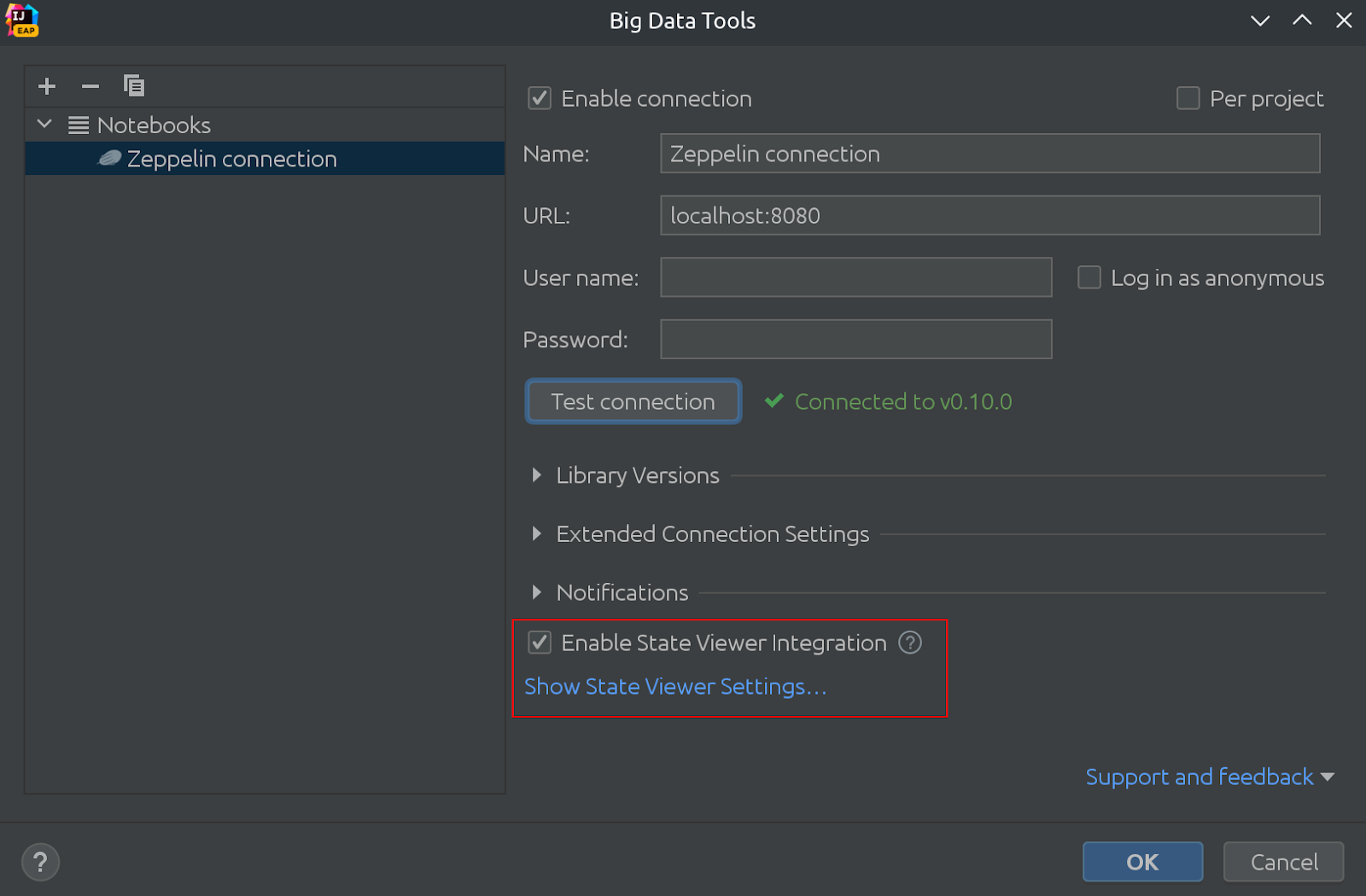
На этой же картинке можно увидеть, что по умолчанию включен просмотр состояния!
Толстый сервер толстому клиенту
Первым существенным изменением, которое мы сделали, стал переход от «тонкого клиента» к «тонкому серверу».Это означает, что IDE не нужно ничего устанавливать в интерпретатор Zeppelin.В свою очередь, это выгодно, когда вы не полностью контролируете пример Zeppelin.
Как это работает?Ну, эти изменения эволюционные, а не эволюционные.Ранее State Viewer использовал исполнение фоновых ячеек только для вызова метода из библиотеки, которую мы установили в интерпретатор Zeppelin.Теперь плагин действует по-разному, выполняя логику сбора данных от Zeppelin и отправляя ее в окно просмотра состояния.
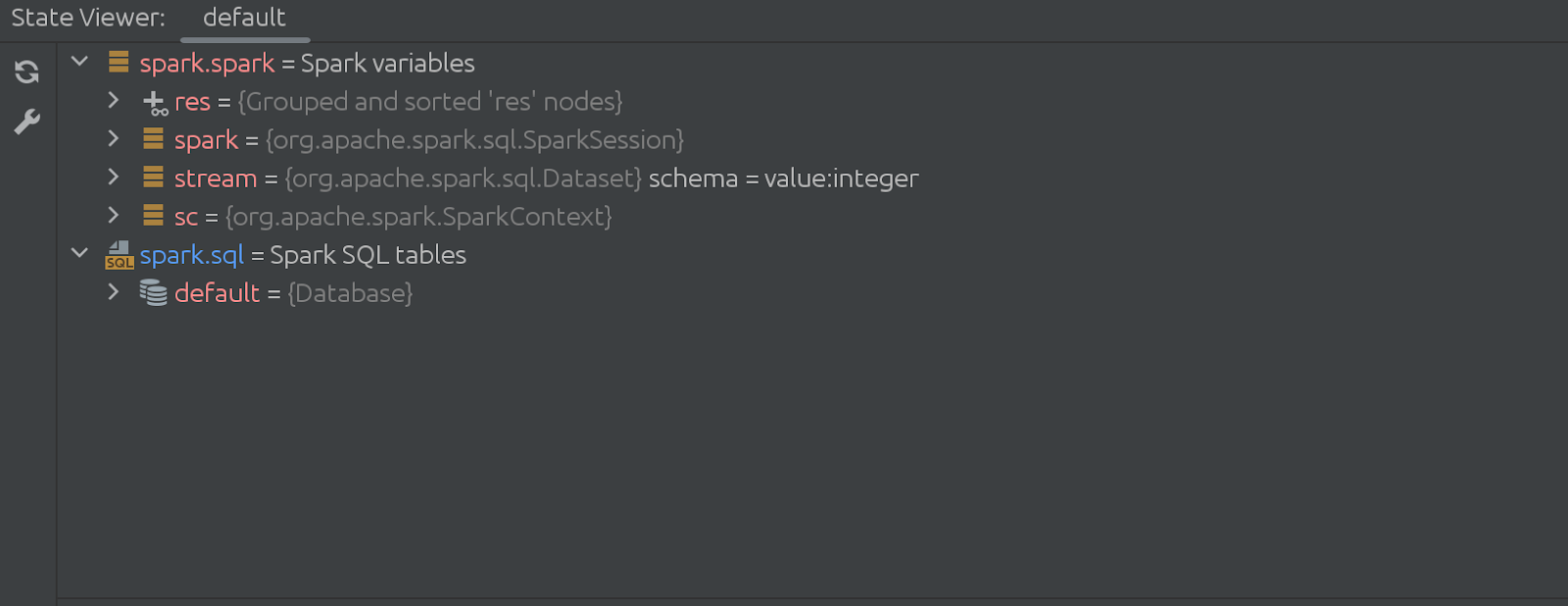
Код скрытой (исчезающей) ячейки тоже впечатляет.Все начинается так:
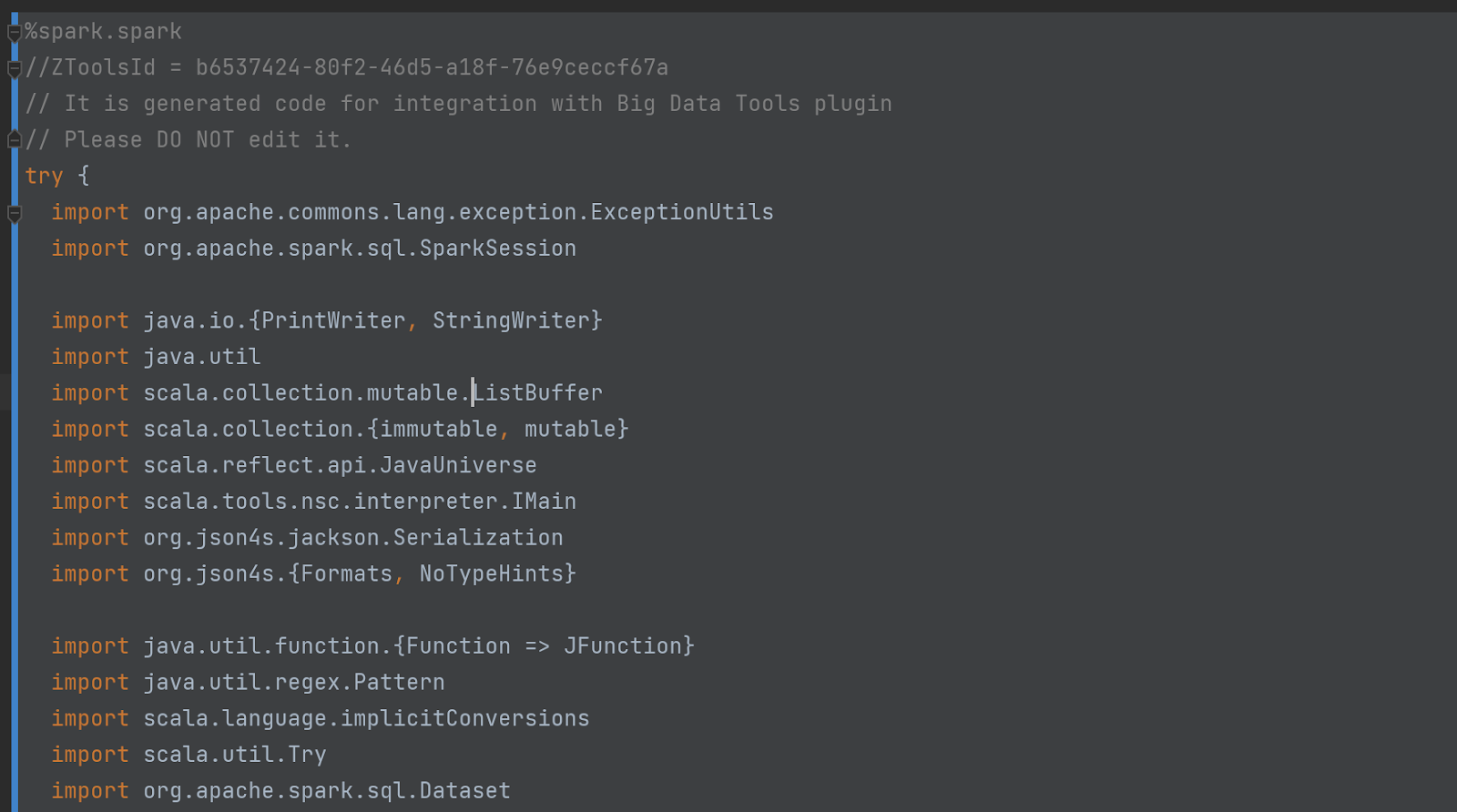
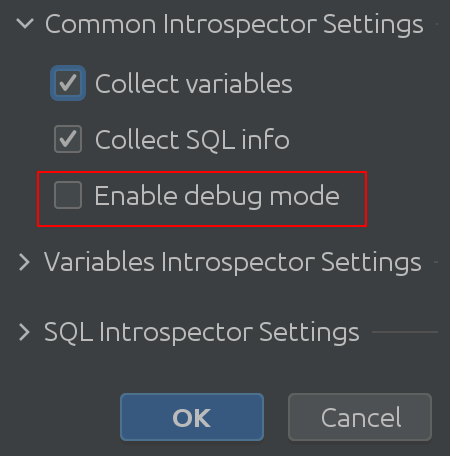
Не верьте нам на слово-проверьте код сами!Для этого включите "режим отладки" в настройках:
Это приводит нас к следующим существенным изменениям: были обновлены настройки State viewer.
Состояние настройки просмотра
Полностью расширенное представление настроек State Viewer выглядит следующим образом:
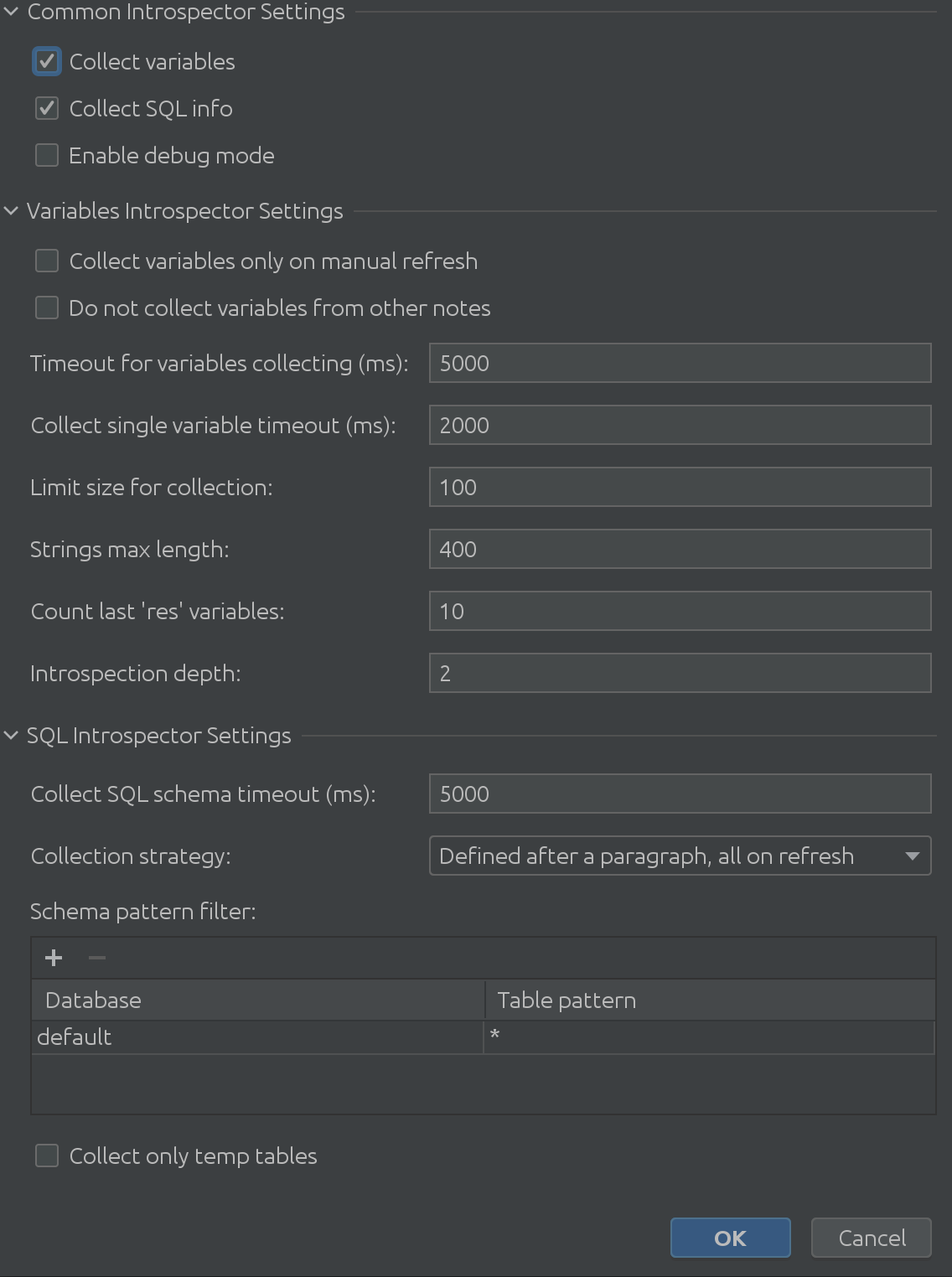
Она абсолютно массивная, да?
Как мы видим на предыдущем скриншоте, он состоит из 3 основных частей:
1. Общие параметры работы переводчика
2. Переменные параметры интроспектора
3. Параметры SQL интроспектора
Надеюсь, что название "общие настройки переводчика" говорит само за себя.Вы можете включить или отключить сбор информации о переменных из Spark SQL, а также включить режим отладки.Конечно, это очень полезно для нас, разработчиков плагинов, но вы можете использовать его, чтобы получить более глубокое понимание внутренней работы плагина.Переменные параметры интроспектора
Ценная обратная связь с нашими клиентами дала нам понимание захватывающих угловых случаев, когда интроспект переменных.Переменные параметры интроспектора охватывают все потенциальные проблемы, с которыми вы можете столкнуться.Нужно интроспецировать более длинные тексты?Увеличить лимит размера строки.Теперь требуется больше времени, чтобы извлечь их все?Увеличить тайм-аут в ожидании ответа Zeppelin.Работать с глубоко вложенными структурами?Вы можете настроить максимальную глубину.
Параметры SQL интроспектора
Мы даже не осознавали, насколько полезен SQL интроспектор для некоторых наших клиентов!E необходимо было выяснить, насколько сложными могут быть сценарии использования для множества схем и таблиц, что привело нас к следующему захватывающему решению:
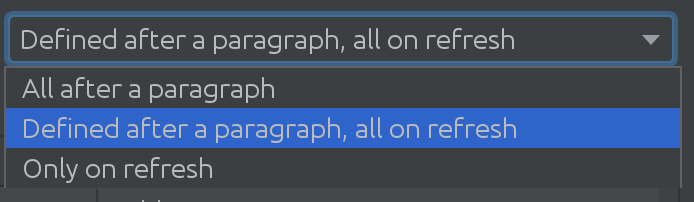
В зависимости от размера базы данных Spark, вы можете использовать различные стратегии, если вам необходимо извлечь изменения из базы данных Spark.Иногда базы данных настолько обширны, что мы не будем автоматически вносить изменения.
Все эти изменения привели к тому, что по умолчанию в этом выпуске мы включили инструменты больших данных.
Мы также узнали, что когда наши клиенты работают с Spark, они работают не только с каталогом по умолчанию.Иногда каталог "по умолчанию" является абсолютно массивным, и они должны каким-то образом фильтровать данные из него.Поэтому мы ввели в SQL интроспектор следующий фильтр:
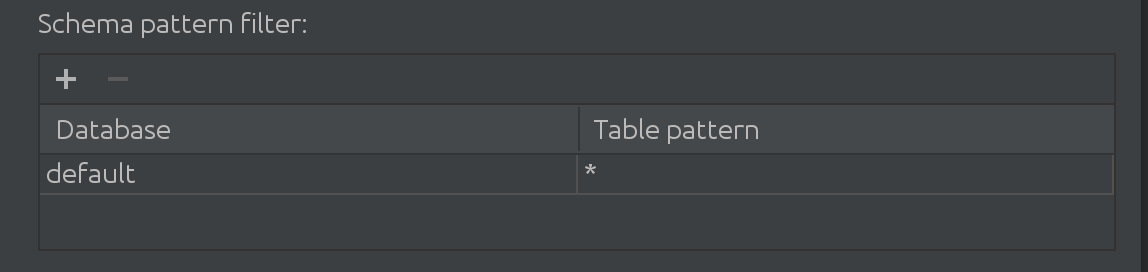
Здесь вы можете фильтровать и добавлять больше каталогов для поиска данных для автозаполнения, а также ограничивать подмножество таблиц в каталоге.
Если вы используете AWS клей или Hive Metastore, вы также можете найти этот флажок полезным:

Клей вашей компании, вероятно, будет невероятно большим, и вам нужны только данные, которые вы положили там во время сеанса.
Просмотр состояния теперь включен по умолчанию
Мы внесли много улучшений с момента нашего последнего сообщения в блоге на эту функцию.Мы очень благодарны нашим клиентам за постоянную поддержку и постоянную обратную связь — благодаря им удалось реализовать многие изменения!В настоящее время мы убеждены в Том, что инструменты больших данных являются достаточно стабильными и гибкими для того, чтобы наша общая аудитория могла постоянно использовать их по следующим причинам:
1. Это больше не требует изменений в Zeppelin.
2. Это позволяет вам настроить переменную интроспективность к вашему варианту использования.
3. Это позволяет настраивать SQL интроспективу в соответствии с контекстом и сложностью задач.
4. Улучшена механика скрытых клеток.
5. У нас есть метод для наших пользователей, чтобы проверить и глубоко понять функциональность плагина.Сделал дополнительный шаг, чтобы позволить нашим клиентам "проверить нас" и убедиться, что мы делаем только то, что мы говорим, что мы делаем, и не более.
Если вы заинтересованы в попытке больших данных инструментов, вы можете легко найти плагин - вот здесь.- да.
 Электронная почта
Электронная почта