คุณจำ เมื่อนานมาแล้วได้หรือไม่เมื่อเราเปิด ตัวฟีเจอร์ในปลั๊กอิน Big Data Tools ที่ชื่อว่า ZTools ซึ่งช่วยให้คุณดูสถานะปัจจุบันของตัวแปรในโน้ตบุ๊ก Zeppelin ได้ คุณจำได้ไหมว่าเราทำการเปลี่ยนแปลงที่สำคัญกับการใช้งาน ZTools เมื่อเกือบปีที่แล้ว
เป็นประเพณีของเราที่จะประกาศเรื่องใหญ่เกี่ยวกับส่วนนี้ของ Big Data Tools เป็นประจำทุกปี และในวันนี้ เราจะประกาศการเปลี่ยนแปลงที่น่าตื่นเต้นหลายรายการ หากคุณต้องการเพียงแค่ตรวจสอบด้วยตัวเอง นี่คือลิงค์ไปยังปลั๊กอิน:
ชื่อใหม่
สิ่งสำคัญที่สุดคือคุณลักษณะนี้เรียกว่า "State Viewer" เราตัดสินใจเปลี่ยนชื่อเนื่องจาก State Viewer สามารถใช้การดูตัวแปรสำหรับโน้ตบุ๊กอื่นๆ ได้เช่นกัน ไม่ใช่แค่สำหรับ Zeppelin มีชื่ออื่นอีกสองสามชื่อที่กำลังพิจารณาอยู่ และการเลือกนั้นไม่ง่ายเลย
นี่คือลักษณะ:
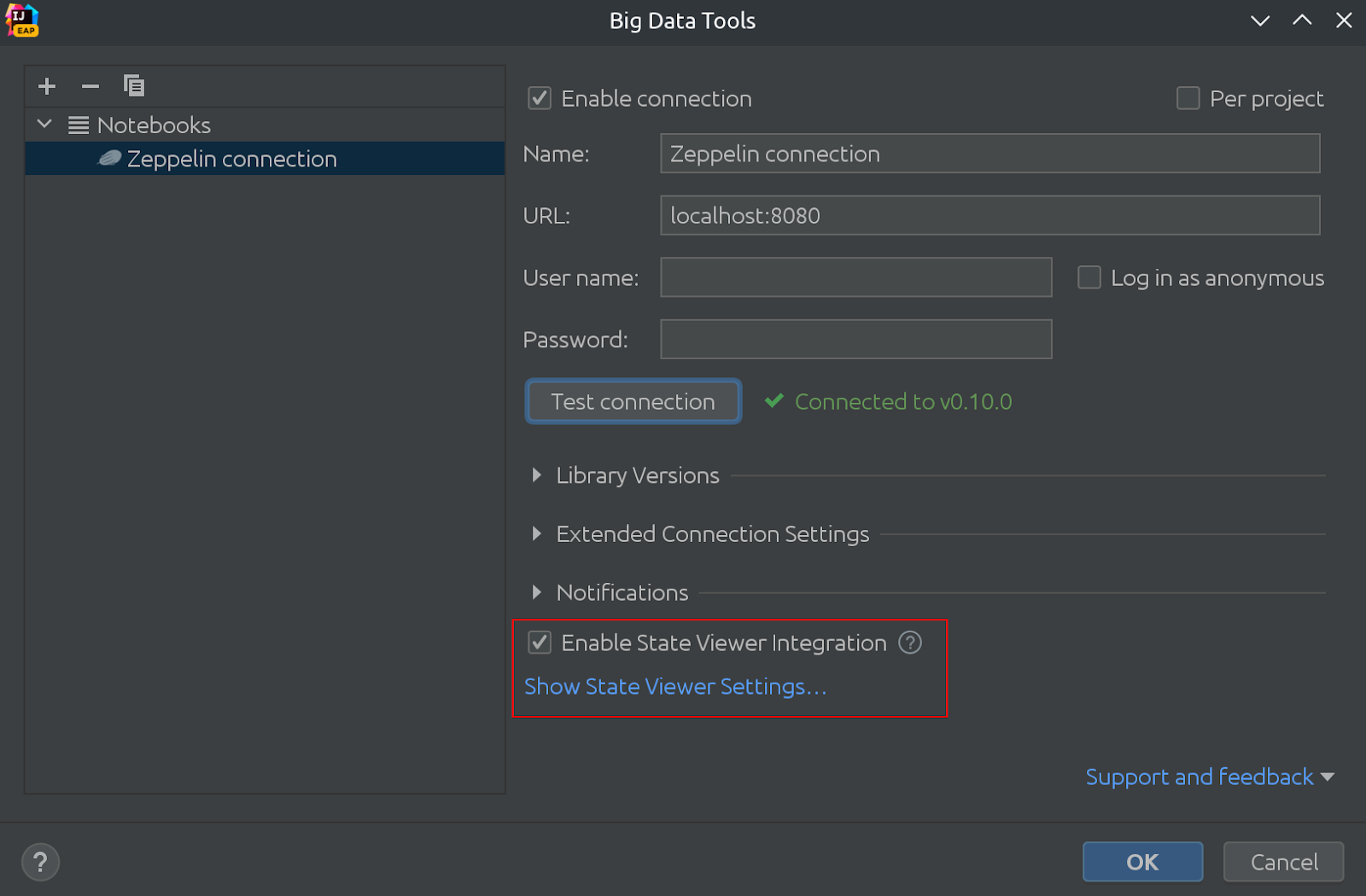
ในภาพเดียวกัน คุณจะเห็นว่าตอนนี้ State Viewer ถูกเปิดใช้งานตามค่าเริ่มต้นแล้ว!
เซิร์ฟเวอร์หนาไปยังไคลเอนต์หนา
การเปลี่ยนแปลงที่สำคัญอย่างแรกที่เราทำคือการย้ายจากโมเดล "thin client" ไปเป็น "thin server" ซึ่งหมายความว่า IDE ไม่จำเป็นต้องติดตั้งสิ่งใดในล่ามของ Zeppelin ในทางกลับกัน สิ่งนี้จะเป็นประโยชน์เมื่อคุณควบคุมอินสแตนซ์ Zeppelin ได้ไม่เต็มที่
มันทำงานอย่างไร? การเปลี่ยนแปลงเหล่านี้เป็นวิวัฒนาการมากกว่าวิวัฒนาการ ก่อนหน้านี้ State Viewer ใช้การทำงานของเซลล์ในพื้นหลังเพื่อเรียกเมธอดจากไลบรารี่ที่เราติดตั้งลงในล่าม Zeppelin เท่านั้น ตอนนี้ปลั๊กอินทำหน้าที่แตกต่างออกไป เรียกใช้ตรรกะการรวบรวมข้อมูลจาก Zeppelin และส่งไปยังหน้าต่าง State Viewer
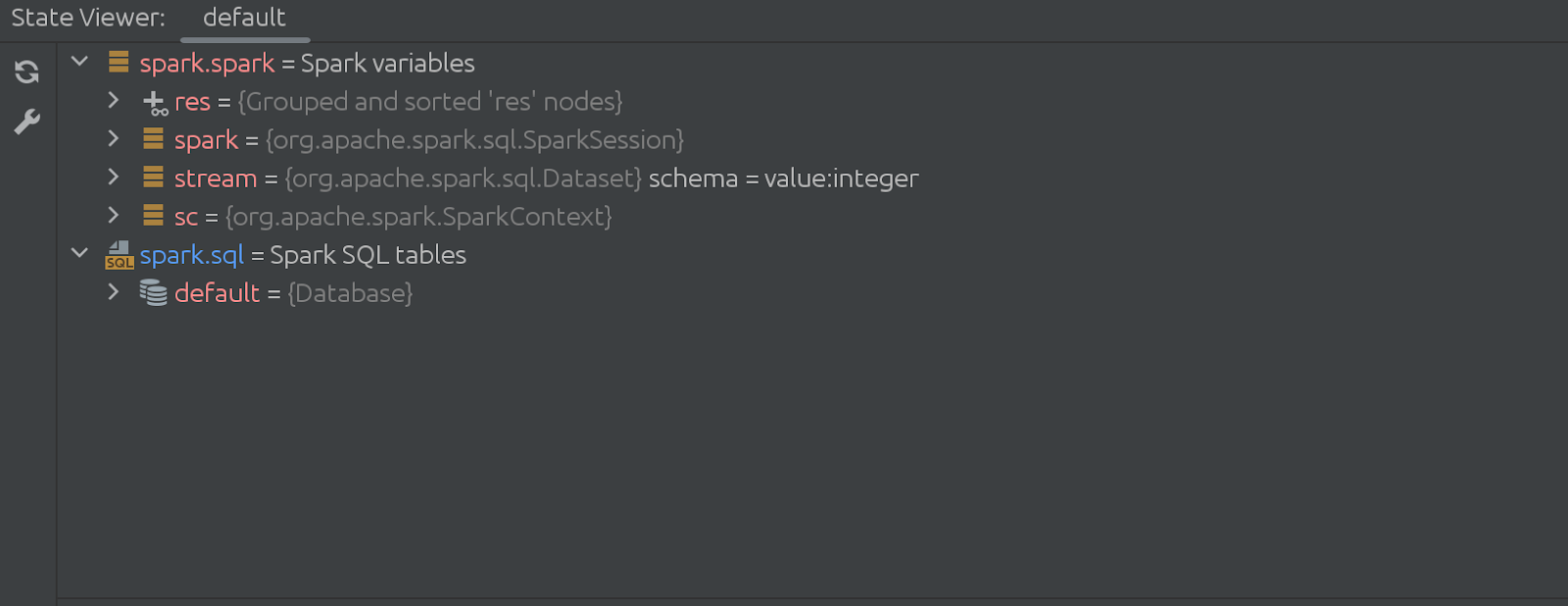
รหัสของเซลล์ที่ซ่อนอยู่ (หายไป) ก็ค่อนข้างน่าประทับใจเช่นกัน มันเริ่มต้นดังนี้:
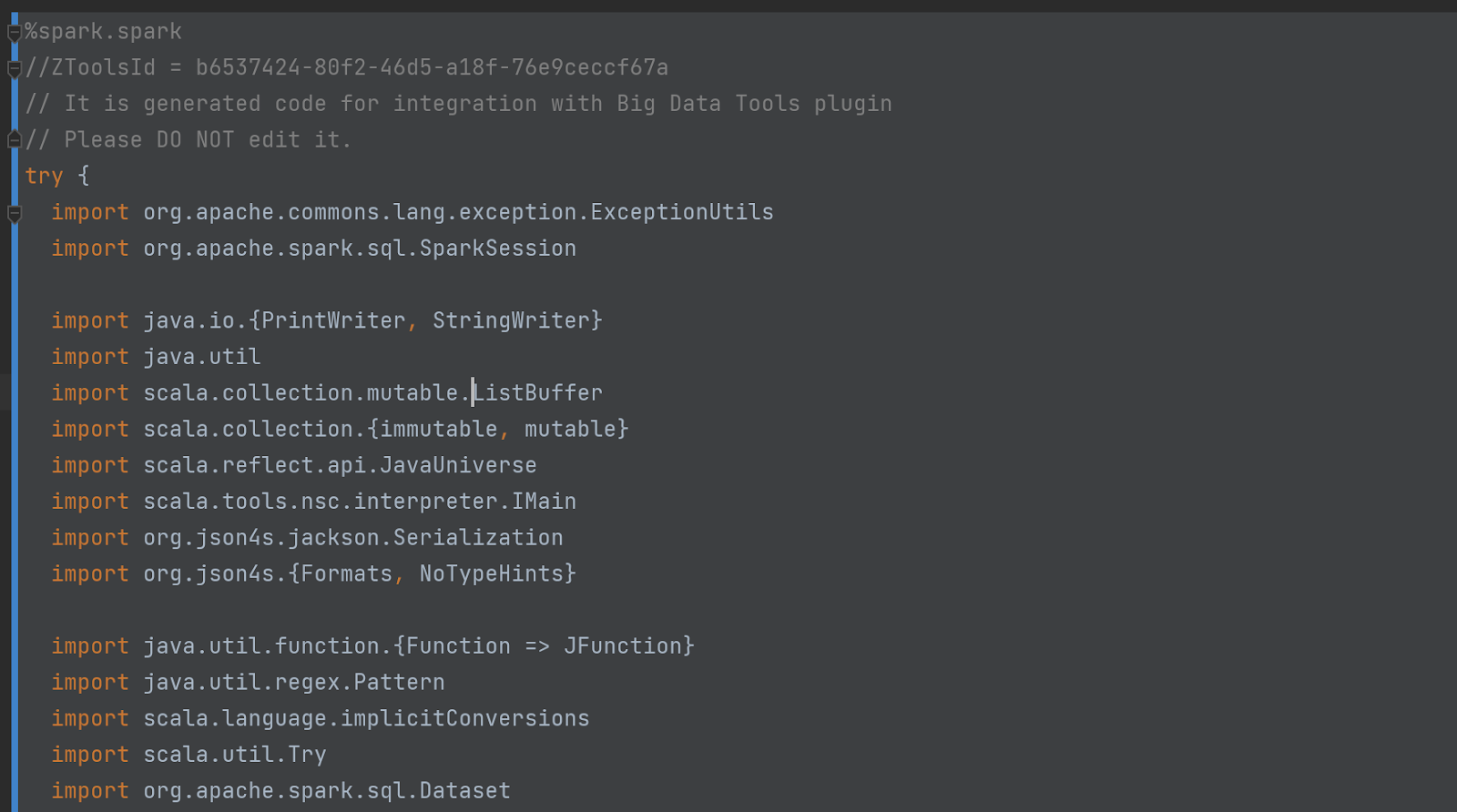
อย่าเชื่อคำพูดของเรา – ตรวจสอบรหัสด้วยตัวคุณเอง! ในการทำเช่นนั้น ให้เปิดใช้งาน “โหมดดีบั๊ก” ในการตั้งค่า:
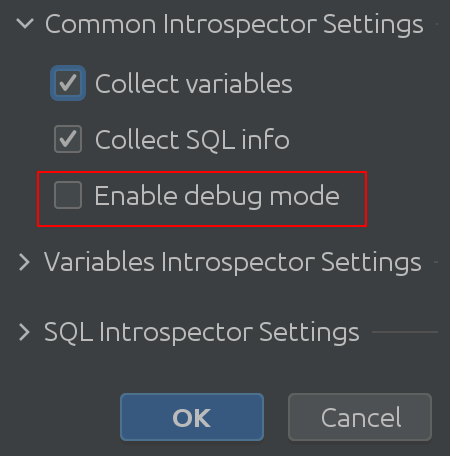
สิ่งนี้นำเราไปสู่การเปลี่ยนแปลงที่สำคัญดังต่อไปนี้: การตั้งค่าตัวแสดงสถานะได้รับการปรับปรุงใหม่
การตั้งค่าตัวแสดงสถานะ
มุมมองที่ขยายเต็มที่ของการตั้งค่า State Viewer มีลักษณะดังนี้:
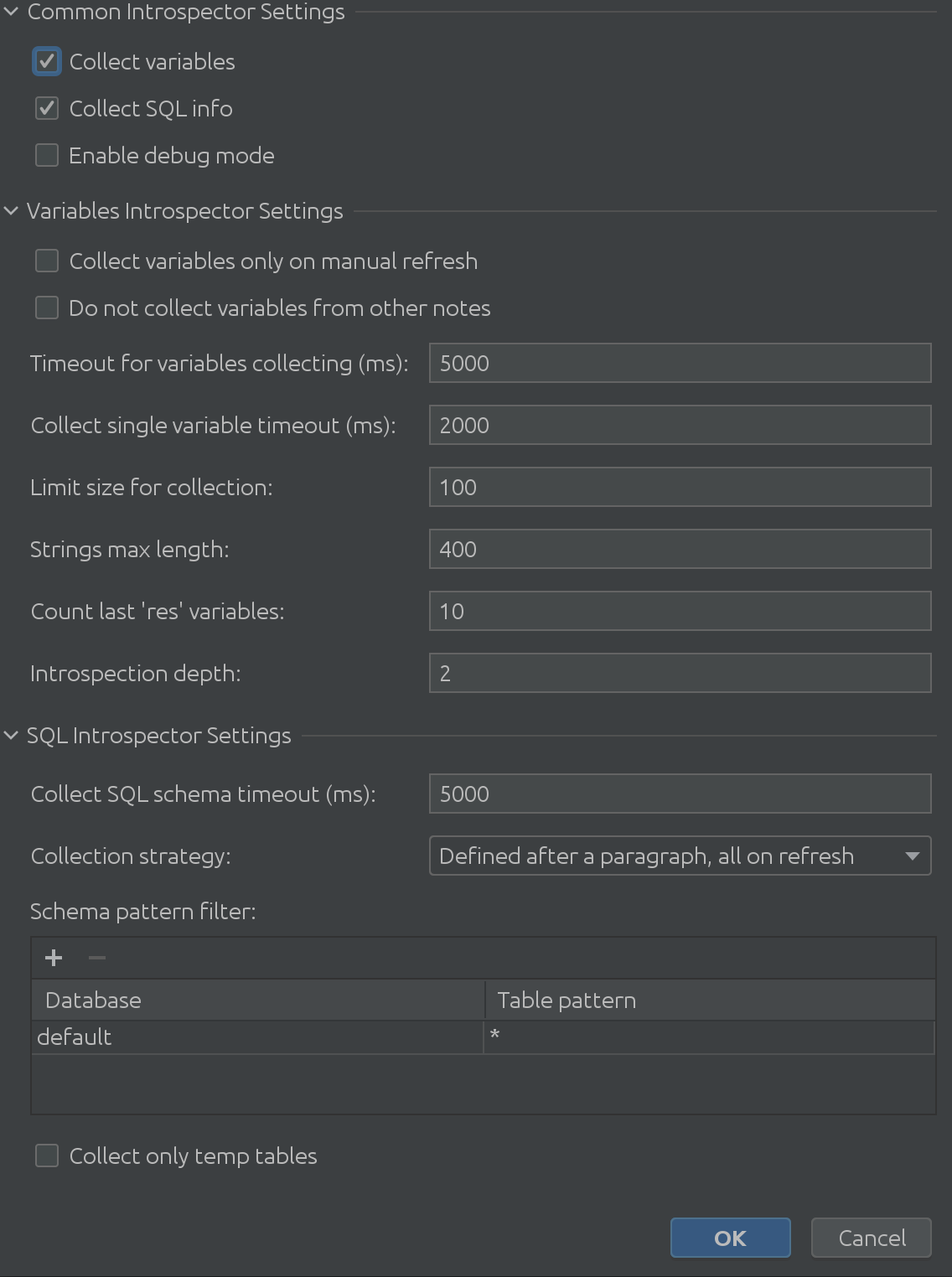
มันใหญ่มากใช่มั้ย?
ดังที่เราเห็นในภาพหน้าจอก่อนหน้านี้ ประกอบด้วย 3 ส่วนหลัก:
1. การตั้งค่าล่ามทั่วไป
2. การตั้งค่า Introspector ตัวแปร
3. การตั้งค่า SQL Introspector
หวังว่าชื่อ “การตั้งค่าล่ามทั่วไป” จะอธิบายได้ในตัวมันเอง คุณสามารถเปิดหรือปิดการรวบรวมข้อมูลเกี่ยวกับตัวแปรจาก Spark SQL และอนุญาตให้คุณเปิดใช้งานโหมดแก้ไขจุดบกพร่อง เป็นที่ยอมรับว่ามีประโยชน์มากที่สุดสำหรับเราซึ่งเป็นผู้พัฒนาปลั๊กอิน แต่คุณสามารถใช้เพื่อทำความเข้าใจการทำงานภายในของปลั๊กอินได้ลึกซึ้งยิ่งขึ้น การตั้งค่า Introspector แบบปรับเปลี่ยนได้
คำติชมอันมีค่าจากลูกค้าของเราทำให้เราเข้าใจกรณีหักมุมที่น่าตื่นเต้นเมื่อพิจารณาตัวแปรต่างๆ การตั้งค่า Introspector แบบแปรผันช่วยแก้ปัญหาที่อาจเกิดขึ้นทั้งหมดที่คุณอาจพบ ต้องการทบทวนข้อความที่ยาวขึ้นหรือไม่? เพิ่มขีดจำกัดของขนาดสตริง ตอนนี้ต้องใช้เวลามากขึ้นในการแยกข้อมูลทั้งหมด? เพิ่มระยะหมดเวลาในขณะที่รอ Zeppelin ตอบ ต้องทำงานกับโครงสร้างที่ซ้อนกันลึกหรือไม่ คุณสามารถปรับความลึกของการขุดสูงสุดได้อย่างละเอียด
การตั้งค่า SQL Introspector
เราไม่รู้ด้วยซ้ำว่า SQL Introspector มีประโยชน์อย่างไรสำหรับลูกค้าบางรายของเรา! จำเป็นต้องค้นหาว่าสถานการณ์การใช้งานที่ซับซ้อนสามารถข้ามสคีมาและตารางจำนวนมากได้อย่างไร ซึ่งนำเราไปสู่โซลูชันที่น่าตื่นเต้นถัดไป:
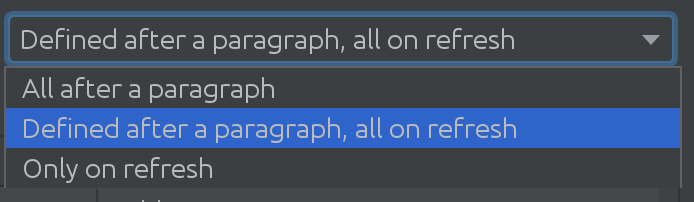
ขึ้นอยู่กับขนาดของฐานข้อมูล Spark ของคุณ คุณสามารถใช้กลยุทธ์ต่างๆ เมื่อต้องการดึงการเปลี่ยนแปลงจากฐานข้อมูล Spark บางครั้งฐานข้อมูลมีมากมายจนเราตัดสินใจไม่ดึงการเปลี่ยนแปลงโดยอัตโนมัติเลย
การเปลี่ยนแปลงทั้งหมดนี้ทำให้เราต้องเปิดเครื่องมือ Big Data ตามค่าเริ่มต้นในรุ่นนี้
เรายังได้เรียนรู้ว่าเมื่อลูกค้าของเราทำงานกับ Spark พวกเขาทำงานมากกว่าแค่แค็ตตาล็อกเริ่มต้น บางครั้งแค็ตตาล็อก "เริ่มต้น" มีขนาดใหญ่มากและจำเป็นต้องกรองข้อมูลจากแคตตาล็อกด้วยวิธีใดวิธีหนึ่ง นั่นเป็นเหตุผลที่เราแนะนำตัวกรองต่อไปนี้ใน SQL Introspector:
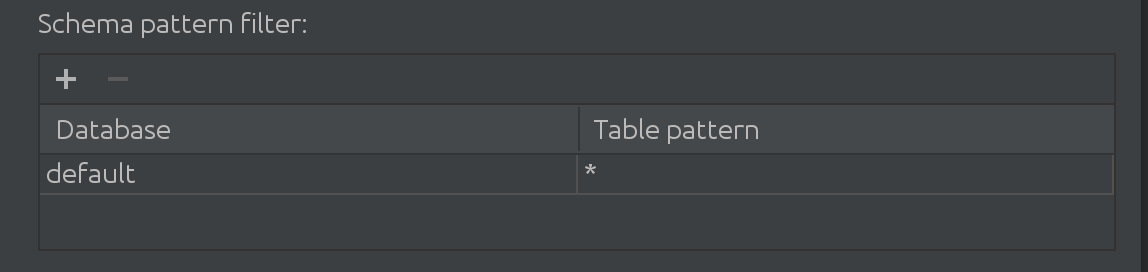
ที่นี่ คุณสามารถกรองและเพิ่มแคตตาล็อกเพิ่มเติมเพื่อค้นหาข้อมูลสำหรับการเติมข้อความอัตโนมัติ รวมทั้งจำกัดชุดย่อยของตารางที่สอบถามภายในแคตตาล็อก
หากคุณใช้ AWS Glue หรือ Hive Metastore คุณอาจพบว่าช่องทำเครื่องหมายนี้มีประโยชน์:

Glue ของบริษัทของคุณน่าจะมีขนาดใหญ่อย่างไม่น่าเชื่อ และคุณต้องการเพียงข้อมูลที่คุณใส่ไว้ในระหว่างเซสชันของคุณเท่านั้น
ขณะนี้ State Viewer ถูกเปิดใช้งานตามค่าเริ่มต้น
เราได้แนะนำการปรับปรุงหลายอย่างตั้งแต่บล็อกโพสต์ครั้งล่าสุดของเราเกี่ยวกับคุณลักษณะนี้ เรารู้สึกขอบคุณลูกค้าเป็นอย่างมากสำหรับการสนับสนุนอย่างต่อเนื่องและข้อเสนอแนะอย่างต่อเนื่อง – การเปลี่ยนแปลงหลายอย่างเป็นไปได้เพราะพวกเขา! ขณะนี้เรามั่นใจว่าเครื่องมือ Big Data มีความเสถียรและยืดหยุ่นเพียงพอสำหรับผู้ชมทั่วไปของเราที่จะสามารถใช้งานได้อย่างต่อเนื่องด้วยเหตุผลเหล่านี้:
1. ไม่ต้องการการเปลี่ยนแปลงใน Zeppelin อีกต่อไป
2. ช่วยให้คุณปรับแต่งการทบทวนตัวแปรตามกรณีการใช้งานของคุณอย่างละเอียด
3. ช่วยให้คุณปรับแต่งการใคร่ครวญ SQL ตามบริบทและความซับซ้อนของงานของคุณ
4. กลไกของเซลล์ที่ซ่อนอยู่ได้รับการปรับปรุง
5. เรามีวิธีให้ผู้ใช้ตรวจสอบและทำความเข้าใจการทำงานของปลั๊กอินอย่างลึกซึ้ง ใช้ขั้นตอนเพิ่มเติมเพื่อให้ลูกค้าของเรา "ตรวจสอบเรา" และตรวจสอบให้แน่ใจว่าเรากำลังทำเฉพาะสิ่งที่เราบอกว่าเรากำลังทำอยู่เท่านั้น ไม่ทำมากกว่านี้
หากคุณสนใจที่จะลองใช้ Big Data Tools คุณสามารถค้นหาปลั๊กอินได้ ที่นี่
 อีเมล
อีเมล