你还记得很久以前,我们在大数据工具插件ZTools中引入了一个功能,允许你查看齐柏林笔记本中变量的当前状态吗?你还记得将近一年前我们对ZTools的实现做了重大改变吗?
我们的传统是每年发布关于大数据工具这一部分的重大公告,今天我们宣布了多个令人兴奋的变化。如果你想自己查看,这里是插件的链接:
新名字
最重要的是,这个特性现在被称为“状态查看器”。我们决定更改名称,因为状态查看器也可以为其他笔记本实现可变查看,而不仅仅是Zeppelin。还有其他几个人也在考虑之中,做出选择并不容易。
这是它的样子:
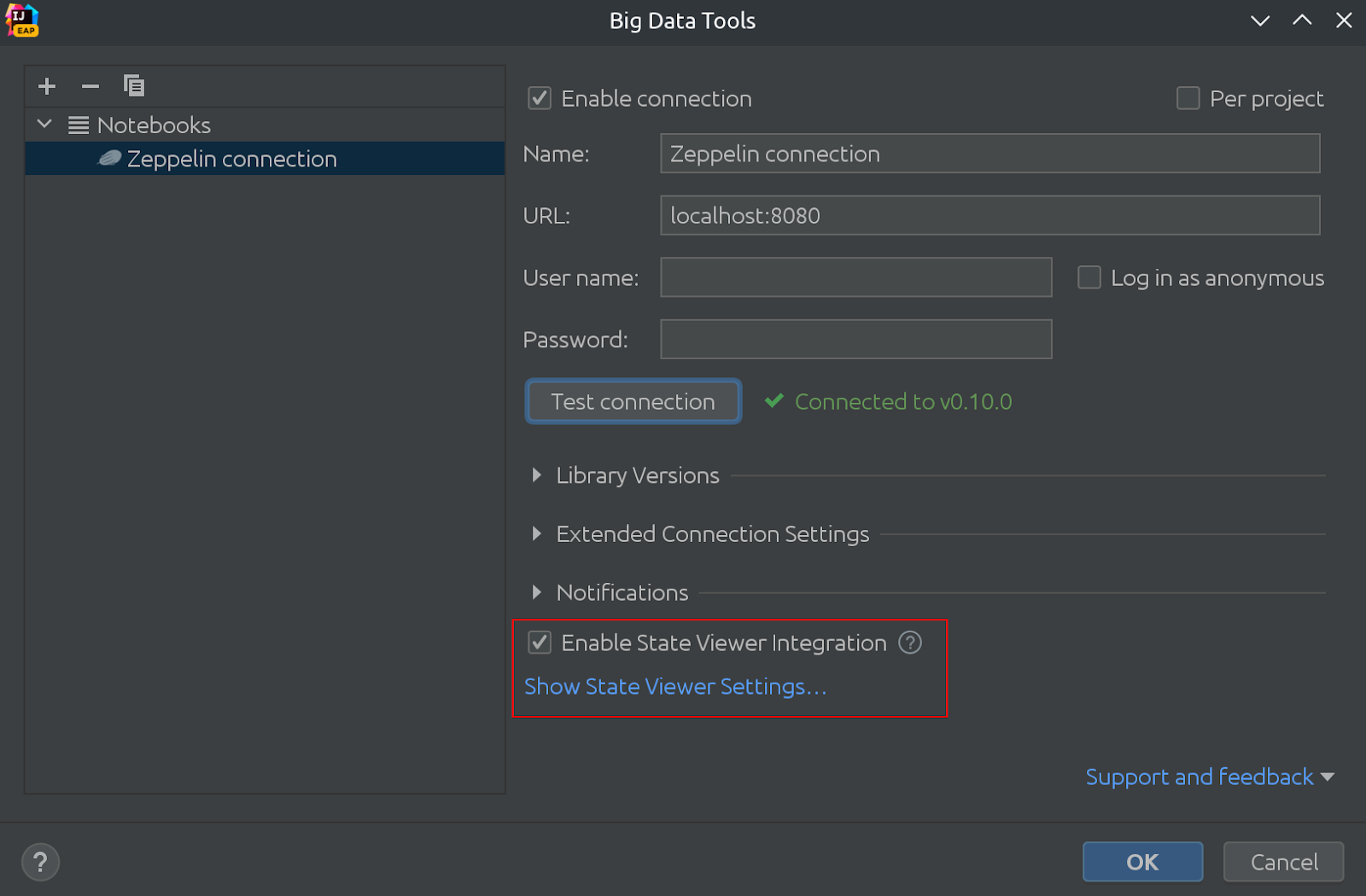
在同一张图中,您可以看到状态查看器现在默认启用!
厚服务器到厚客户端
我们所做的第一个重大改变是从“瘦客户端”模型转向“瘦服务器”模型。这意味着IDE不需要在Zeppelin的解释器中安装任何东西。反过来,当您不能完全控制Zeppelin实例时,这是有益的。
它是如何工作的?这些变化是进化的,而不是进化的。以前,状态查看器只使用后台单元格执行来调用我们安装到Zeppelin解释器中的库中的方法。现在插件的行为不同了,它从Zeppelin执行数据收集逻辑,并将其发送到状态查看器窗口。
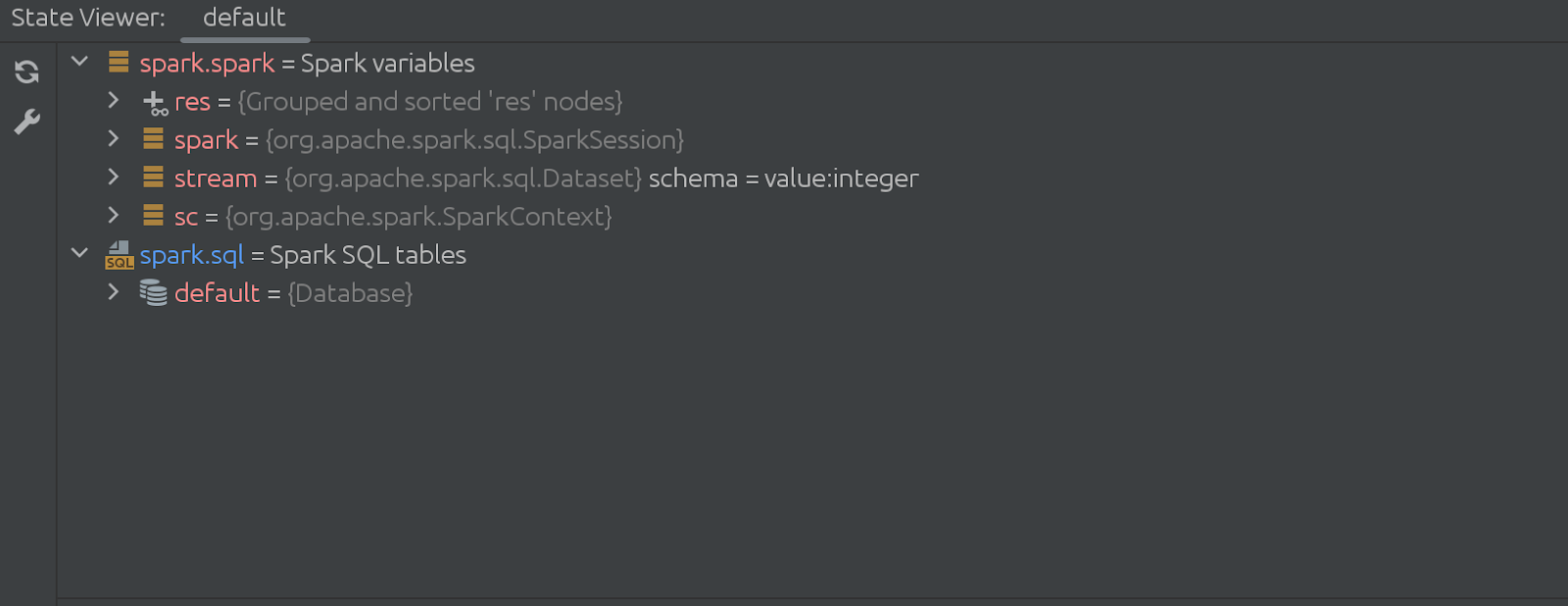
隐藏(消失)单元格的代码也令人印象深刻。开头是这样的:
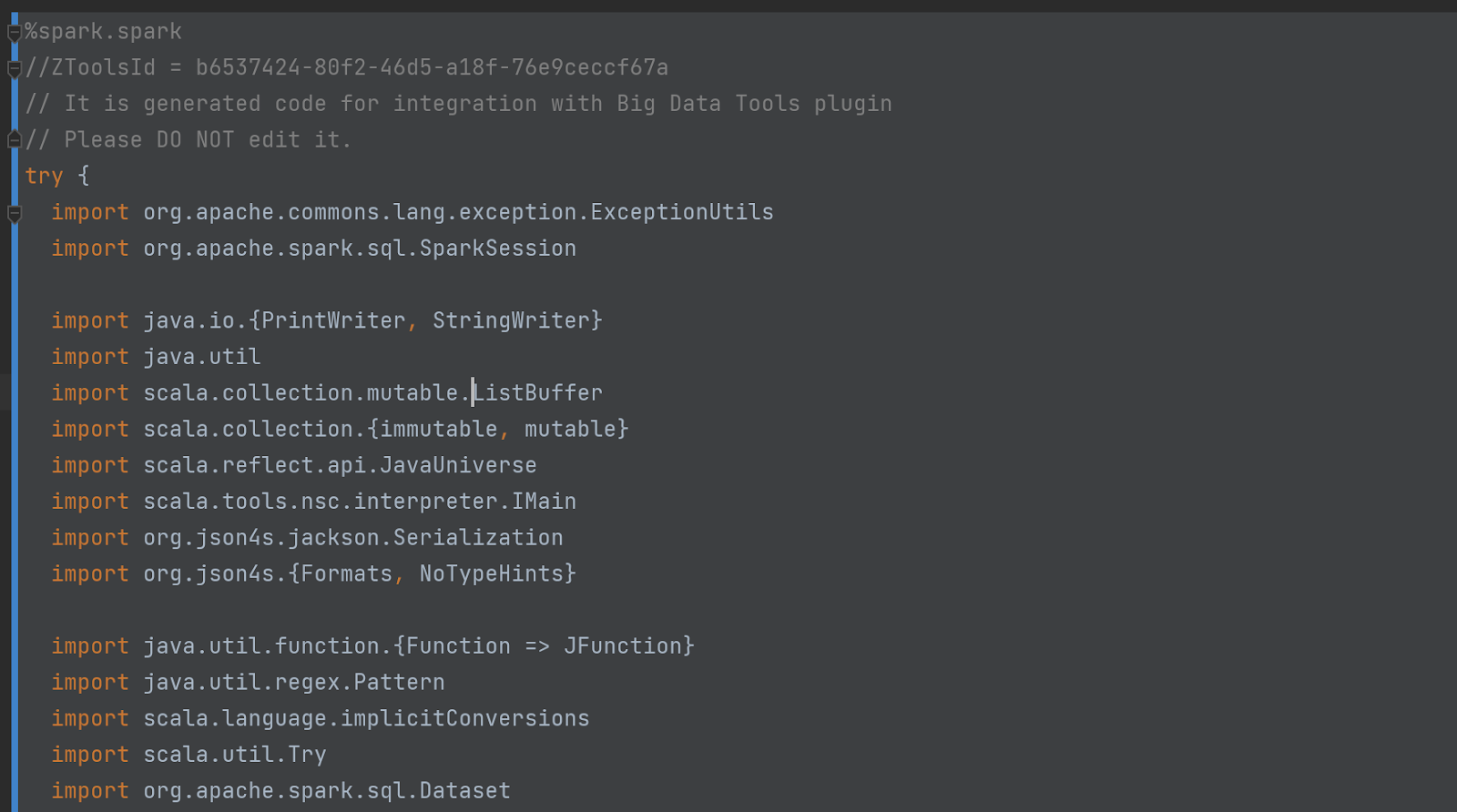
不要相信我们的话——你自己去看看代码吧!为此,在设置中启用“调试模式”:
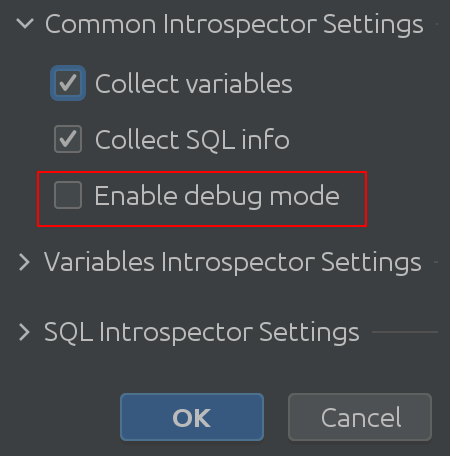
这将导致以下重大更改:状态查看器设置已进行了修改。
状态查看器设置
状态查看器设置的完全展开视图如下所示:
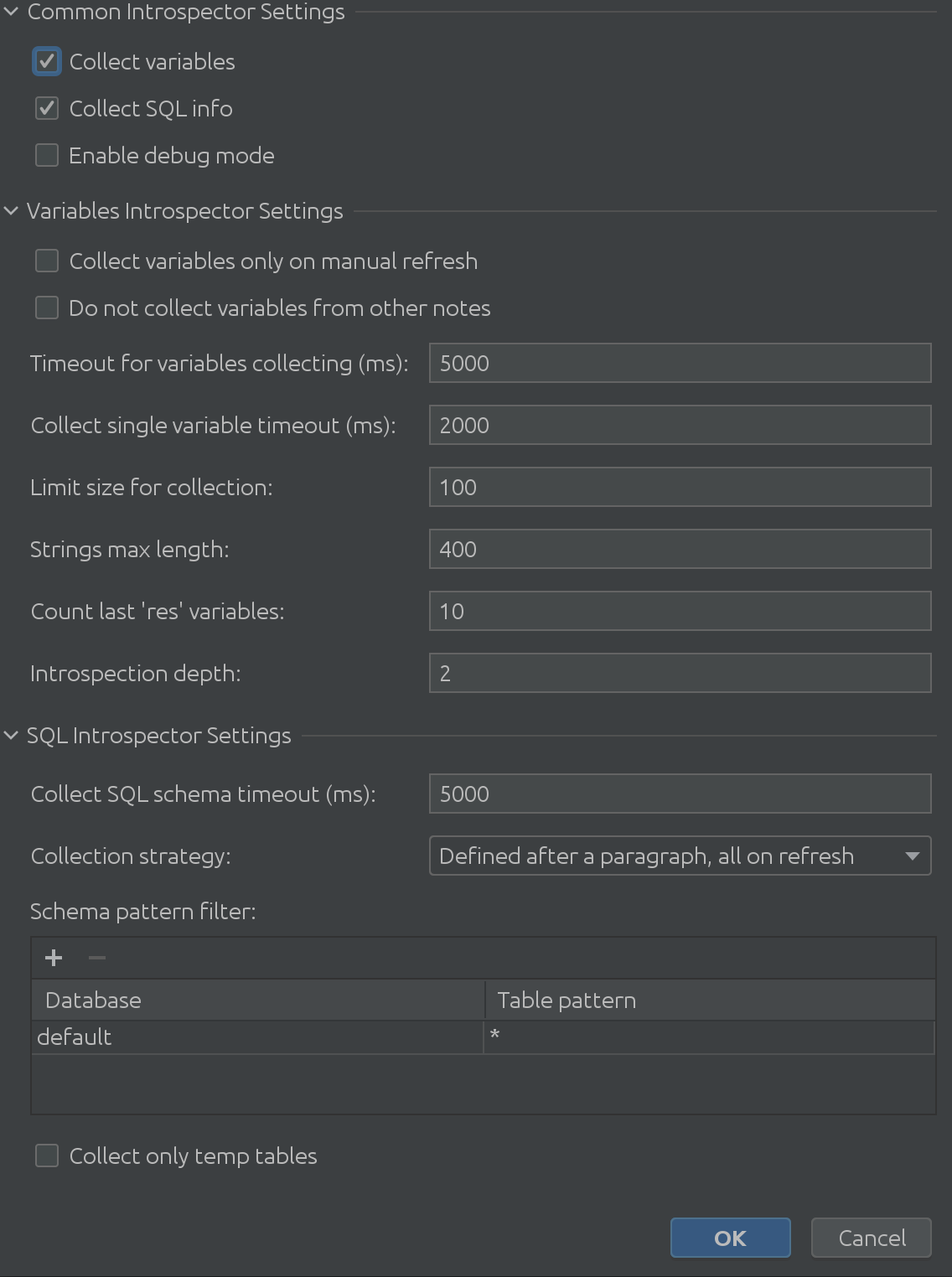
它绝对是巨大的,对吧?
正如我们在之前的截图中看到的,它由3个主要部分组成:
1. 常用解释器设置
2. 变量自省器设置
3.SQL Introspector设置
希望“通用解释器设置”这个名称是不言自明的。您可以从Spark SQL中启用或禁用关于变量的信息收集,并允许您启用调试模式。诚然,这对我们插件开发人员来说是最有用的,但你可以用它来更深入地了解插件的内部工作原理。变量自省器设置
来自客户的有价值的反馈让我们在自省变量时了解了令人兴奋的极端情况。变量自省设置解决了您可能遇到的所有潜在问题。需要自省较长的文本?增加字符串大小的限制。现在要花更多时间把它们都取出来?增加等待齐柏林应答的超时时间。必须使用深度嵌套的结构?您可以微调最大挖掘深度。
SQL Introspector设置
我们甚至没有意识到SQL Introspector对我们的一些客户是多么有用!E需要找出跨许多模式和表的使用场景有多复杂,这使我们找到了下一个令人兴奋的解决方案:
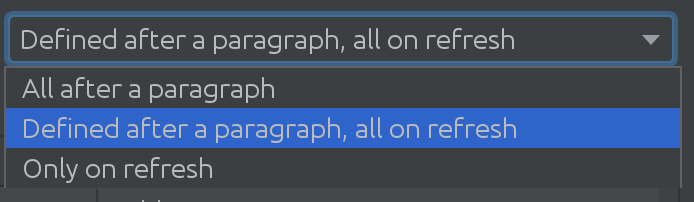
根据Spark数据库的大小,当需要从Spark数据库中提取更改时,可以使用不同的策略。有时数据库是如此广泛,以至于我们决定根本不自动拉取更改。
所有这些变化使我们在这个版本中默认开启了大数据工具。
我们还了解到,当我们的客户使用Spark时,他们使用的不仅仅是默认目录。有时,“默认”目录非常庞大,他们需要以某种方式从中过滤数据。这就是为什么我们在SQL Introspector中引入了下面的过滤器:
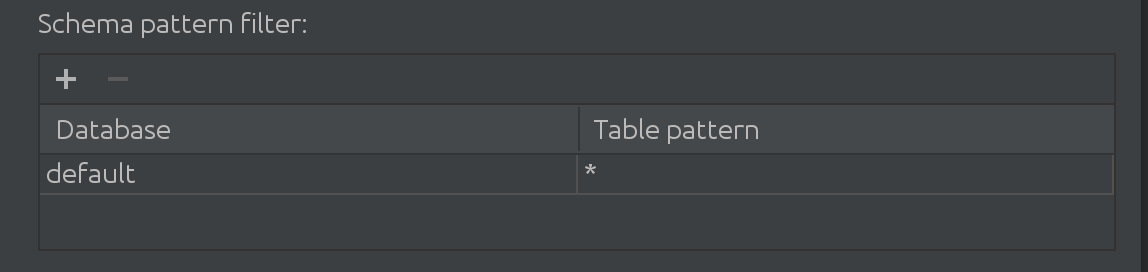
在这里,您可以过滤和添加更多的目录,以查找用于自动补全的数据,以及限制目录中查询的表的子集。
如果你使用AWS Glue或Hive Metastore,你可能也会发现这个复选框很有用:

您公司的Glue可能非常大,您只需要在会话期间放入其中的数据。
状态查看器现在默认启用
自上一篇关于该功能的博文以来,我们已经介绍了许多改进。我们非常感谢我们的客户持续的支持和持续的反馈-因为他们才有可能实施许多更改!我们现在很有信心,大数据工具足够稳定和灵活,我们的普通用户能够持续使用它,原因如下:
1. 它不再需要改变齐柏林。
2. 它允许您根据用例微调变量自省。
3.它允许您根据任务的上下文和复杂性调优SQL自省。
4. 隐藏细胞的机制得到了改进。
5. 我们为用户提供了一种检查和深入理解插件功能的方法。采取了额外的步骤,让我们的客户“检查我们”,并确保我们只做我们所说的,而不是更多。
如果你有兴趣尝试大数据工具,你可以很容易地在这里找到这个插件。
 电子邮件
电子邮件